开发第一个采集器
如何基于集蜂云平台快速开发第一个采集器,下面介绍大概的流程。
开发流程
- 创建项目
- 安装依赖,
pip install beeize-sdk-python - 编写 main.py ,应用代码
- 编写 requirements.txt ,依赖包
- 编写 Dockerfile ,镜像打包
- 编写 input_schema.json ,应用发布后的输入项
- 编写 output_schema.json ,运行结果的展示概览
- 编写 README.md , 应用的使用指南
示例代码请查看: beeize-scraper-example。
项目目录结构参考
your_project/
requirements.txt
input_schema.json
Dockerfile
output_schema.json
README.md
main.py
sdk 输出目录结构参考
storage/
datasets/
default/
000000001.json
000000002.json
000000003.json
000000004.json
__metadata__.json
kv_stores/
default/
demo1.mp4
demo2.mp4
demo3.mp4
demo4.mp4
__metadata__.json
request_queues/
default/
8m3Ssk32vNgBp4p.json
9NQYbiNlWlaJYci.json
09nTuJT7y87FGXs.json
EmPwJk4NaJQPzpS.json
__metadata__.json
main文件示例
import json
import requests
from beeize.scraper import Scraper
from loguru import logger
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 ('
'KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
}
def fetch(url, retry_count=0):
try:
response = requests.get(
url=url,
headers=headers
)
return response.json()
except (Exception,):
if retry_count < 3:
return fetch(url, retry_count + 1)
def main():
scraper = Scraper() # 注意:scraper 要全局唯一,scraper是线程安全的
queue = scraper.request_queue
kv_store = scraper.key_value_store
visit_user_token = 'MS4wLjABAAAAiAce5qhH31TeuB3UdpFMV8u-uwy2LnoiqI10uZHqAt8'
start_url = f'https://www.toutiao.com/api/pc/feed/?category=profile_all&utm_source=toutiao&visit_user_token={visit_user_token}&max_behot_time=0&_signature='
# 添加初始请求任务到队列
queue.add_request({'url': start_url, 'type': 'profile'})
while queue.is_finished():
# 消费队列中的请求任务
request = queue.fetch_next_request()
if not request:
break
logger.info(request)
url = request['url']
# 下载请求
resp = fetch(url)
if not resp:
# 对失败请求进行标记
queue.reclaim_request(request)
continue
# 对成功请求进行标记
queue.mark_request_as_handled(request)
# 解析列表页
if request['type'] == 'profile':
for item in resp.get('data'):
item_id = item.get('item_id')
item['type'] = 'basic'
# 存储到 datasets
scraper.push_data(item)
logger.info(item)
# 添加详情页请求任务到队列
queue.add_request({
'url': f'https://m.toutiao.com/i{item_id}/info/',
'type': 'detail',
'item_id': item_id,
})
# 解析详情页
if request['type'] == 'detail':
item = resp.get('data')
item['url'] = url
item['type'] = 'complete'
# 存储到 datasets
scraper.push_data(item)
item_id = request.get('item_id')
# 存储文件到 kv_store
kv_store.set_value(item_id, json.dumps(item, ensure_ascii=False, indent=4))
logger.info(item) # 日志
if __name__ == '__main__':
main()
Dockerfile示例
Python 项目可参考如下 Dockerfile:
# 使用 Python 官方镜像作为基础镜像,如果代码需要 node 环境运行 js,可以把基础镜像 python:3.8 替换成 nikolaik/python-nodejs:latest
FROM python:3.8
# 设置工作目录
WORKDIR /app
# 复制项目文件到容器中
COPY ./main.py ./main.py
COPY ./requirements.txt ./requirements.txt
# 安装依赖
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 设置环境变量,可选项,TZ 是特定的一个环境变量,用来设置容器时间时区,不设置的话默认是 UTC 时区,打印日志时间是 UTC 时间
ENV TZ=Asia/Shanghai
# 设置容器启动时执行的命令
CMD python main.py
input_schema 示例
input_schema.json 定义了采集器的输入,平台会把 input_schema.json 界面化显示,方便用户配置参数。 平台将用户输入参数转换为环境变量,采集器在运行的时候,通过环境变量获得用户输入的参数。
使用流程如下:
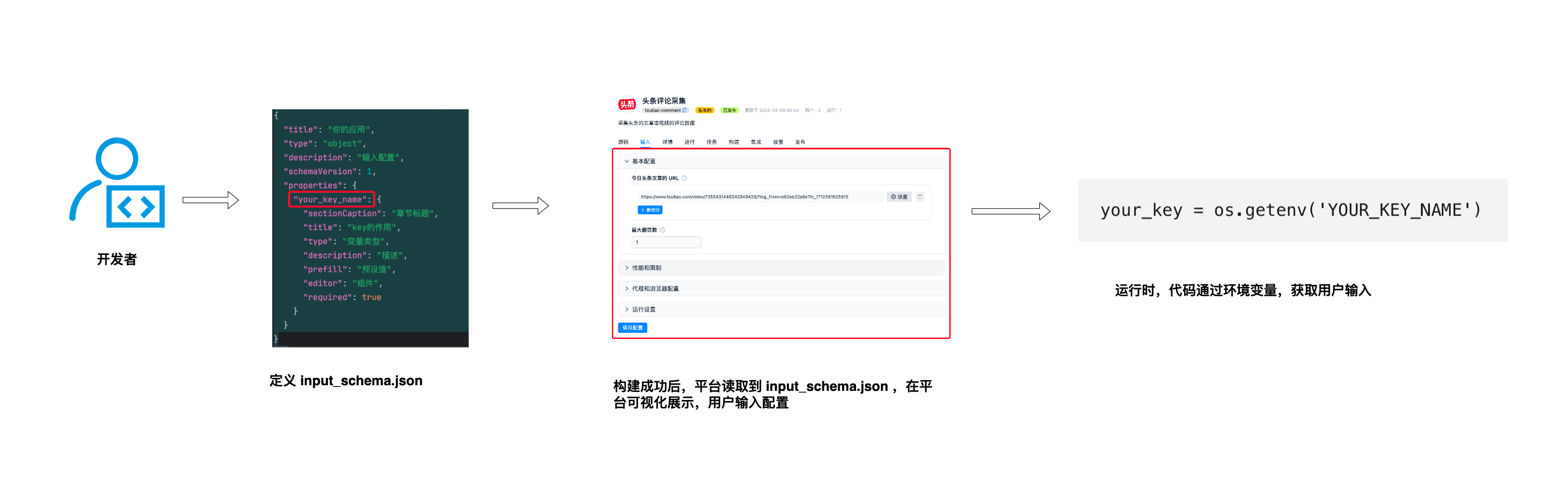
参数详细定义,请参考 输入</a>。
output_schema示例
output_schema 用来帮助用户更好的理解数据含义,平台根据 output_schema.json 的定义来可视化展示数据。 目前,平台支持的数据类型(type字段)包括 string、number、array、image、link、object、bool 7 种类型。
详细请参考 输出。
{
"component": "table",
"columns": {
"title": {
"title": "标题",
"type": "string"
},
"author": {
"title": "作者",
"type": "string"
},
"publish_time": {
"title": "发布时间",
"type": "string"
},
"content": {
"title": "正文",
"type": "string"
},
"images": {
"title": "图片",
"type": "array"
},
"url": {
"title": "内容页链接",
"type": "string"
},
"list_page": {
"title": "列表页链接",
"type": "string"
}
}
}
README.md 示例
README.md 是用来介绍你的采集器,让用户更加理解采集器,从而选择使用你的采集器。
README 可以按照下面的提纲进行编写:
- 首先整体介绍下采集器采集的站点、采集内容、采集器的特点;
- 使用方法:逐个介绍输入中的选项,以及设置的选项可能对用户带来的影响。如果比较复杂,甚至可以录一个视频;
- 样例数据:介绍下采集的数据,可以提供样例数据截图(截图可以上传到免费的图床);
- 常见问题:收集用户反馈的问题以及解决办法
发布到集蜂云平台
最后,可以把开发的采集器发布到集蜂云平台,发布方法请参考如何发布自己的采集器。
上一篇:强大的分布式爬虫平台
下一篇:军队采购网招投标信息监控
导航目录