与其他采集器
集蜂云平台支持与其他采集器进行集成,大大扩展了集成的能力。对于一些复杂的数据处理流程,可以通过配置多个集成来完成。
配置方法
选择连接其他采集器
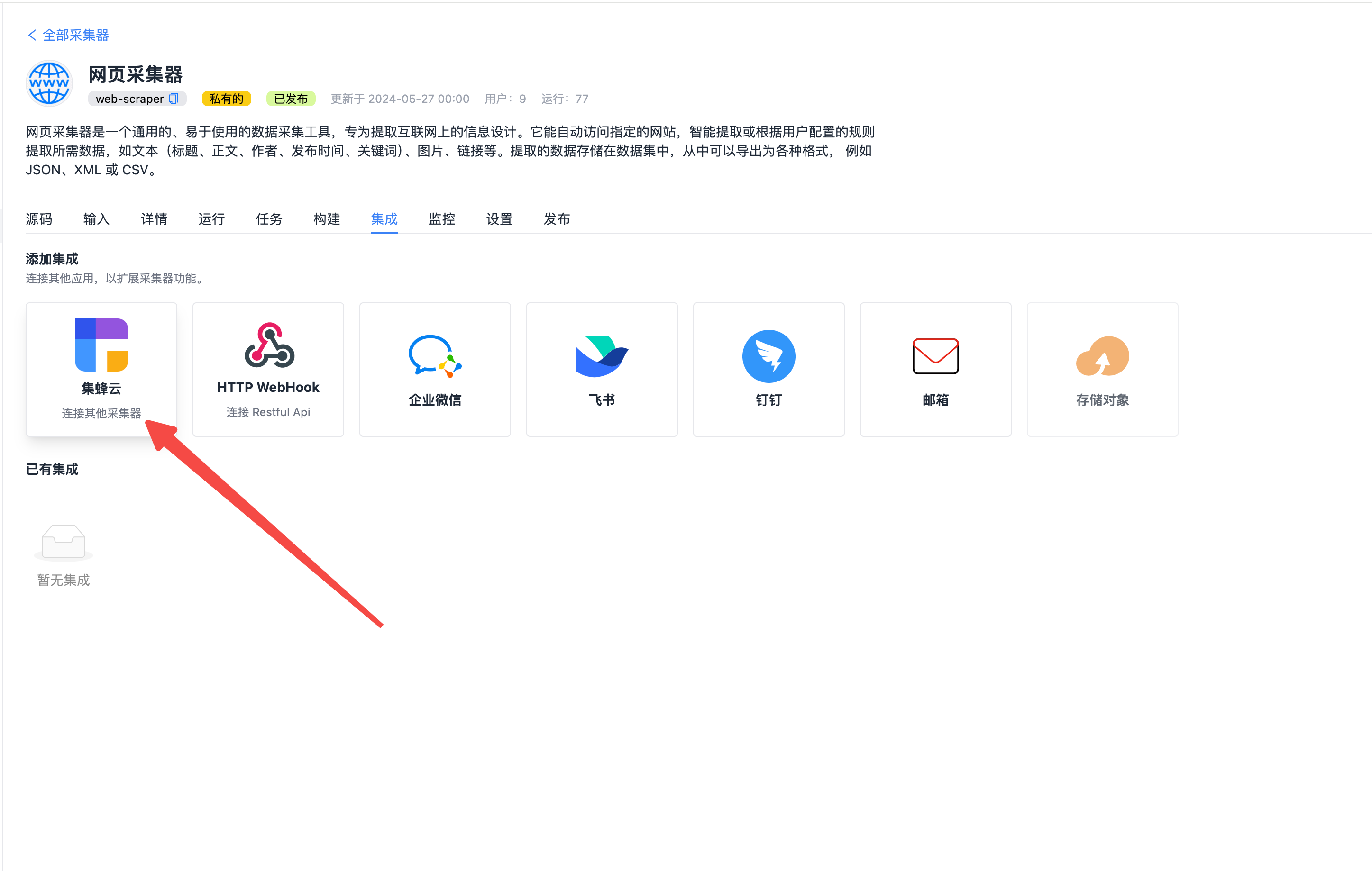
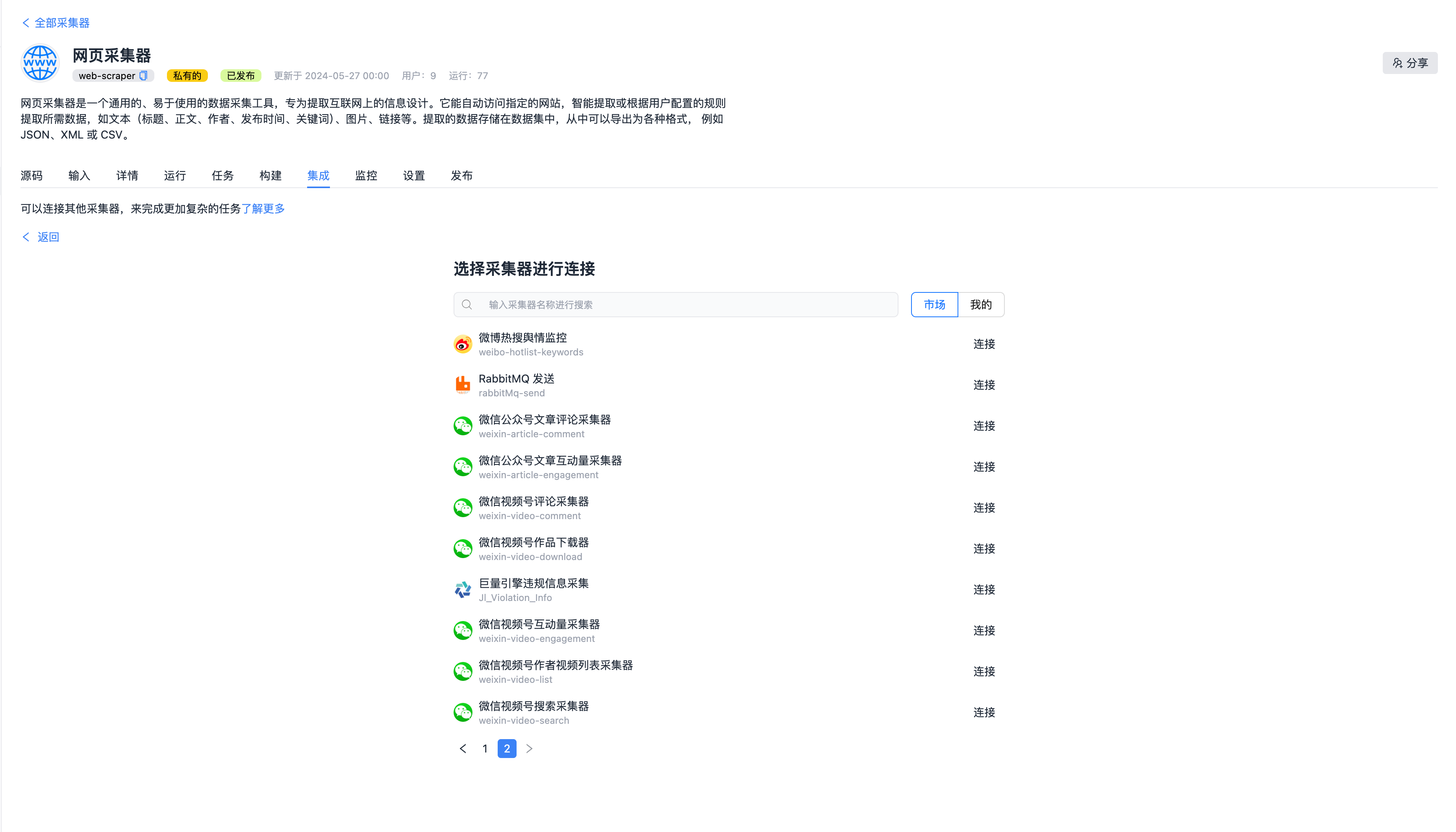
选择需要连接的采集器,比如选择 RabbitMQ,可以将采集到的数据发送到 RabbitMQ 消息队列中去。
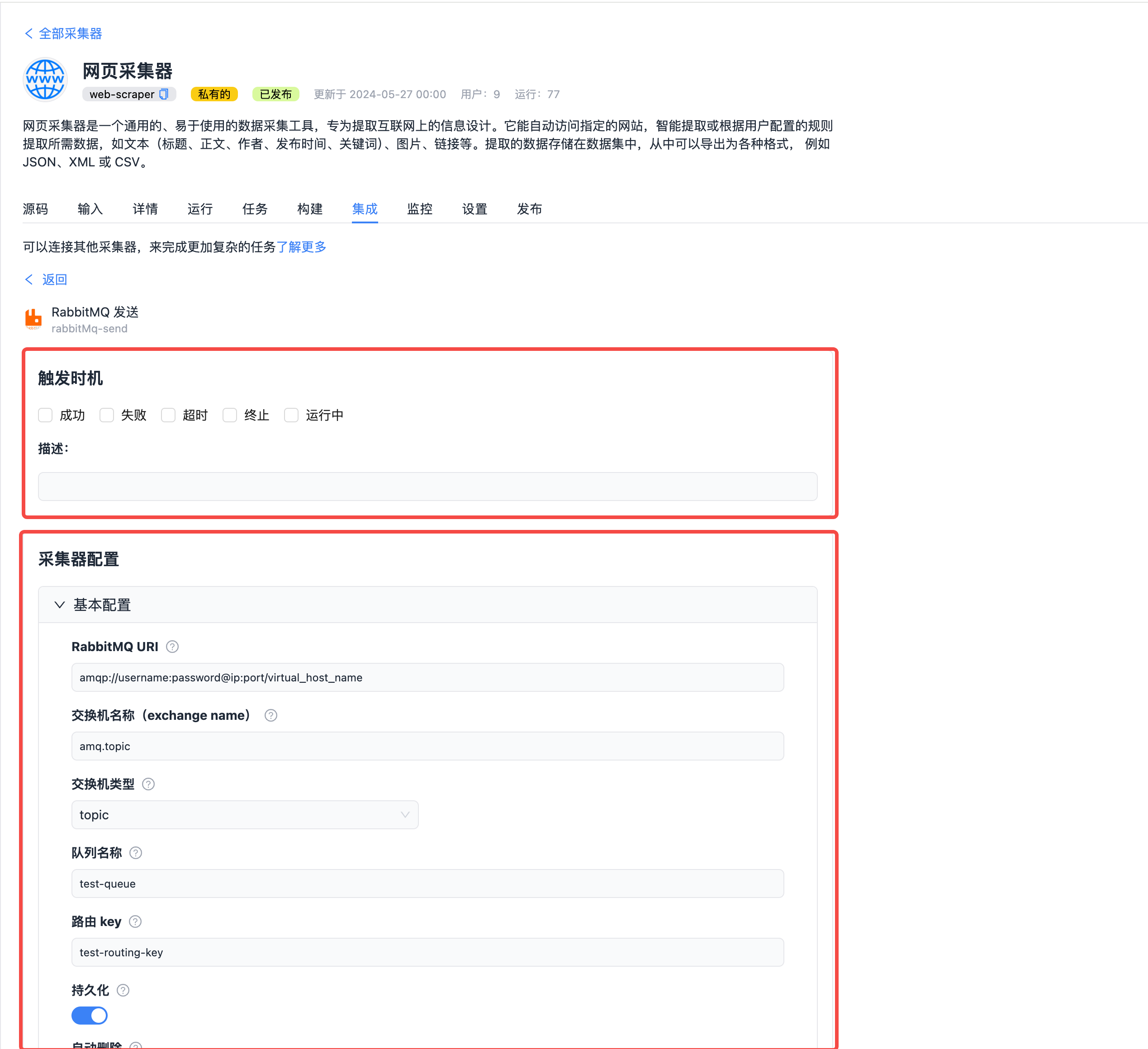
配置采集器。一是配置触发时机,二是配置连接的采集器的基本信息。
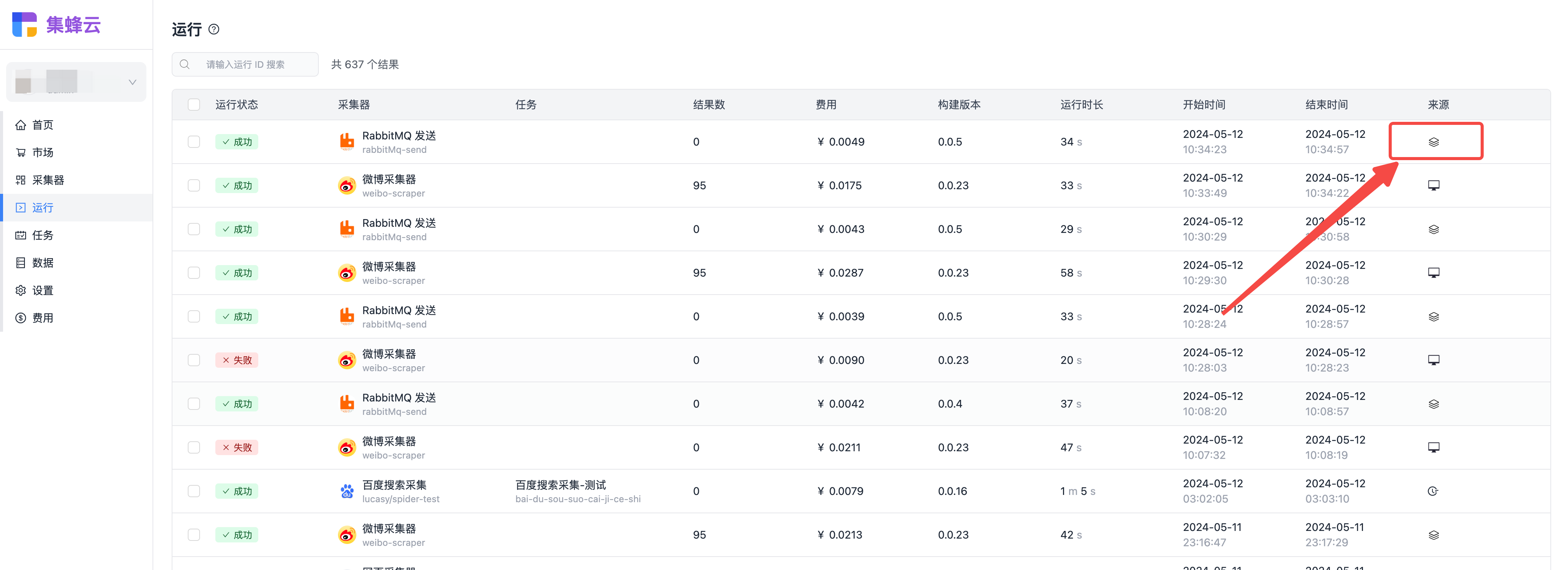
运行方式
如果采集器或者任务(称为父任务)配置了与其他采集器(称为子任务)的集成,当采集器或者任务运行结束(或者达到触发时机)时,会发起所集成的采集器的运行。
子任务的采集器能够通过 /payload目录共享到父任务的数据,并通过 PAYLOAD环境变量获取父任务的运行 ID、datasets id
等信息。
运行集成的标识:
开发自己的采集器集成
用户可以根据自身的需求来开发采集器集成。采集器集成的输入与输出与普通采集器一样,区别在于运行时的采集器集成可以获取到父任务的信息。
1、获取父任务的运行信息
通过环境变量PAYLOAD获取父任务的运行信息,PAYLOAD 是一个 json,格式如下:
{"runId":"xxx","kvStoreId":"xx","datasetId":"xx","requestQueueId":"xx"}
通过解析此 json ,能够获取到父任务的 runId、datasetId、kvStoreId、requestQueueId 信息。
2、获取父任务的数据集
通过环境变量PAYLOAD_PATH获取父任务的数据集路径,一般情况下,父任务的数据集路径为 /payload。
3、读取父任务的数据
数据集
父任务的数据集(datasets)路径为:
/payload/datasets/{datasetId}
通过读取 /payload/datasets/{datasetId}/__metadata__.json 获取数据集数据条数:
__metadata__.json 文件内容:
{
"id": "xxx", // 运行id
"itemCount": 19, // 数据集数据量
"accessedAt": "2024-05-28T08:59:07.558887+00:00",
"createdAt": "2024-05-28T08:58:28.946898+00:00",
"modifiedAt": "2024-05-28T08:59:07.558908+00:00"
}
数据集的文件名是从 000000001 开始编号,位数固定:
000000001.json
000000002.json
000000003.json
……
键值对
父任务的键值对(kvStore)路径为:
/payload/kv_stores/{kvStoreId}
采集队列
父任务的采集队列(requestQueueId)路径为:
/payload/request_queues/{requestQueueId}