输入
input_schema 定义了采集器的输入,它是一个 JSON 对象,用来描述提供给用户输入的每个字段。平台会根据字段的描述,来自动生成对应的界面显示,从而方便用户输入。
平台获取用户输入后,将每个字段以及字段的输入值,转换为采集器运行时的环境变量,采集器从环境变量中获取用户的输入信息。
输入项会在转为环境变量时变成大写。例如,会将 key 为 user_name ,在环境变量中 key 转换为 USER_NAME。
规范
基本输入
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
"your_key_name": {
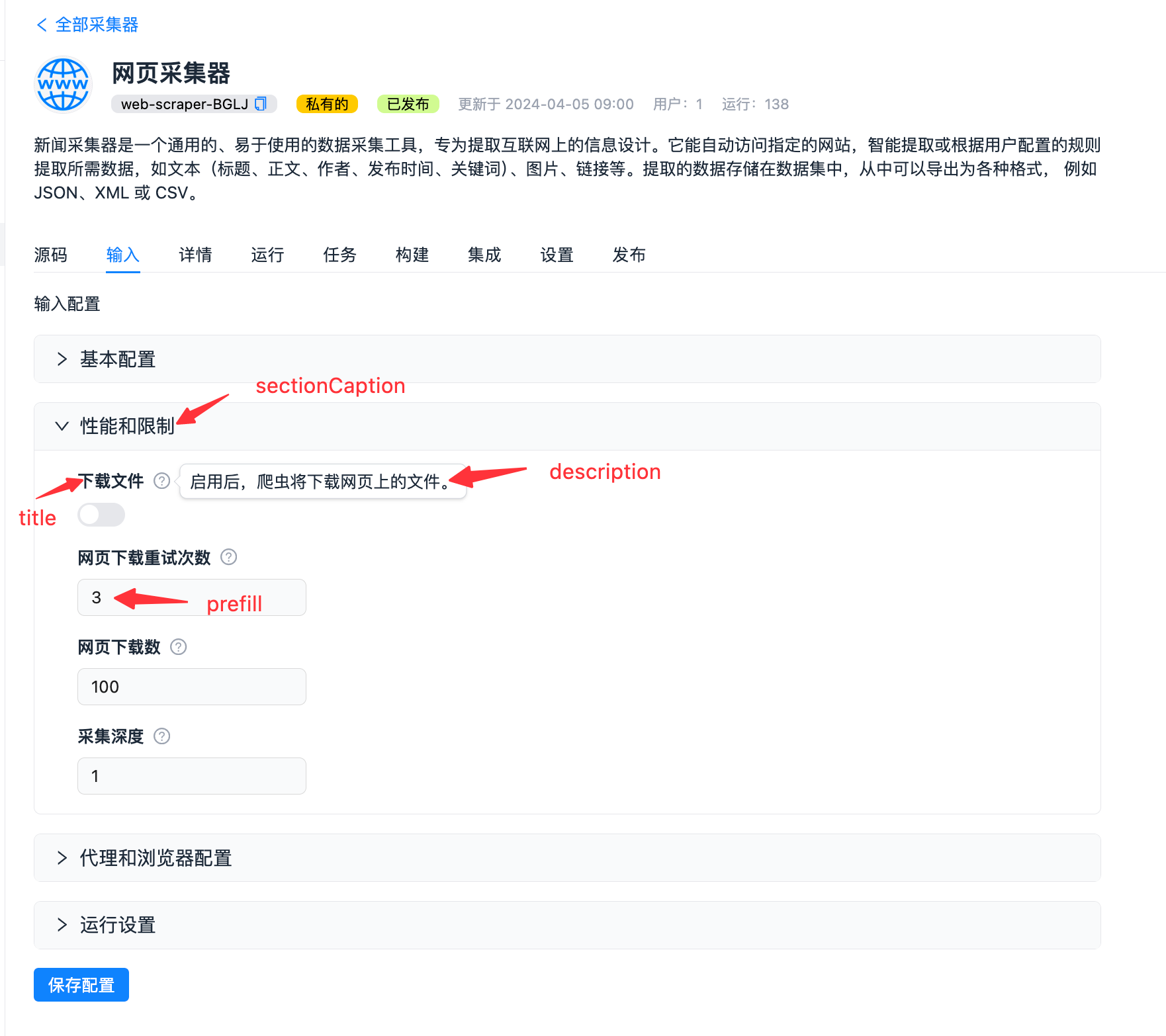
"sectionCaption": "章节标题",
"title": "key的作用",
"type": "变量类型",
"description": "描述",
"prefill": "预设值",
"editor": "组件",
"required": true
}
}
}
| 字段 | 类型 | 是否必须 | 描述 |
|---|---|---|---|
| title | string | 是 | input_schema 的标题,不会显示在界面上 |
| type | string | 是 | 必须设置为 object |
| description | string | 否 | 输入的帮助信息,将会显示在输入界面的上方。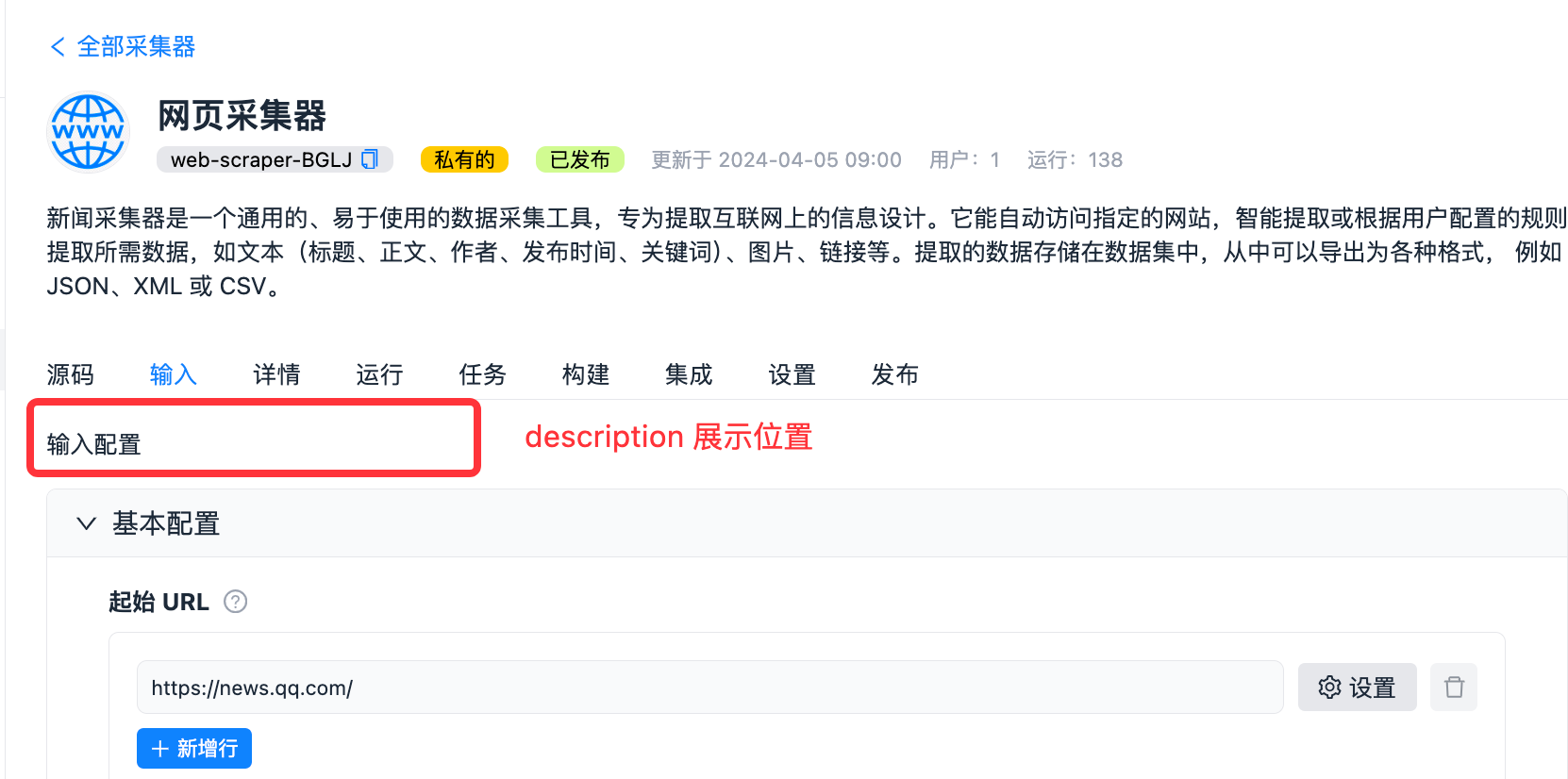 |
| schemaVersion | number | 是 | schema 格式版本,目前是 1。 |
| properties | object | 是 | 输入字段的描述,详细描述见下面的字段描述 |
字段描述
properties 对象描述的是每个输入字段,其描述定义如下:
| 字段 | 类型 | 是否必须 | 描述 |
|---|---|---|---|
| title | string | 是 | key 的名称,显示在界面上 |
| type | string | 是 | 该字段数据类型,为 integer, string, array, object 或 boolean等 |
| description | string | 是 | 该字段的详细描述信息 |
| prefill | string | 否 | 该字段的预设值,需要与 type 字段类型保持一致 |
| required | bool | 否 | 是否必填,默认为 false。如果 true ,界面会做必填校验 |
| editor | string | 否 | 样式组件,复杂输入或者特殊样式需要此字段。目前支持的组件有 select、textfield、requestListSources、json等,详细描述见下面的组件 |
| sectionCaption | string | 否 | 如果设置了此属性,则此字段后面的所有字段(包括此字段)将被收纳为一个可折叠面板,并将设置的值作为其标题。该折叠结束于下一个字段设置了 sectionCaption 属性或者是最后一个字段。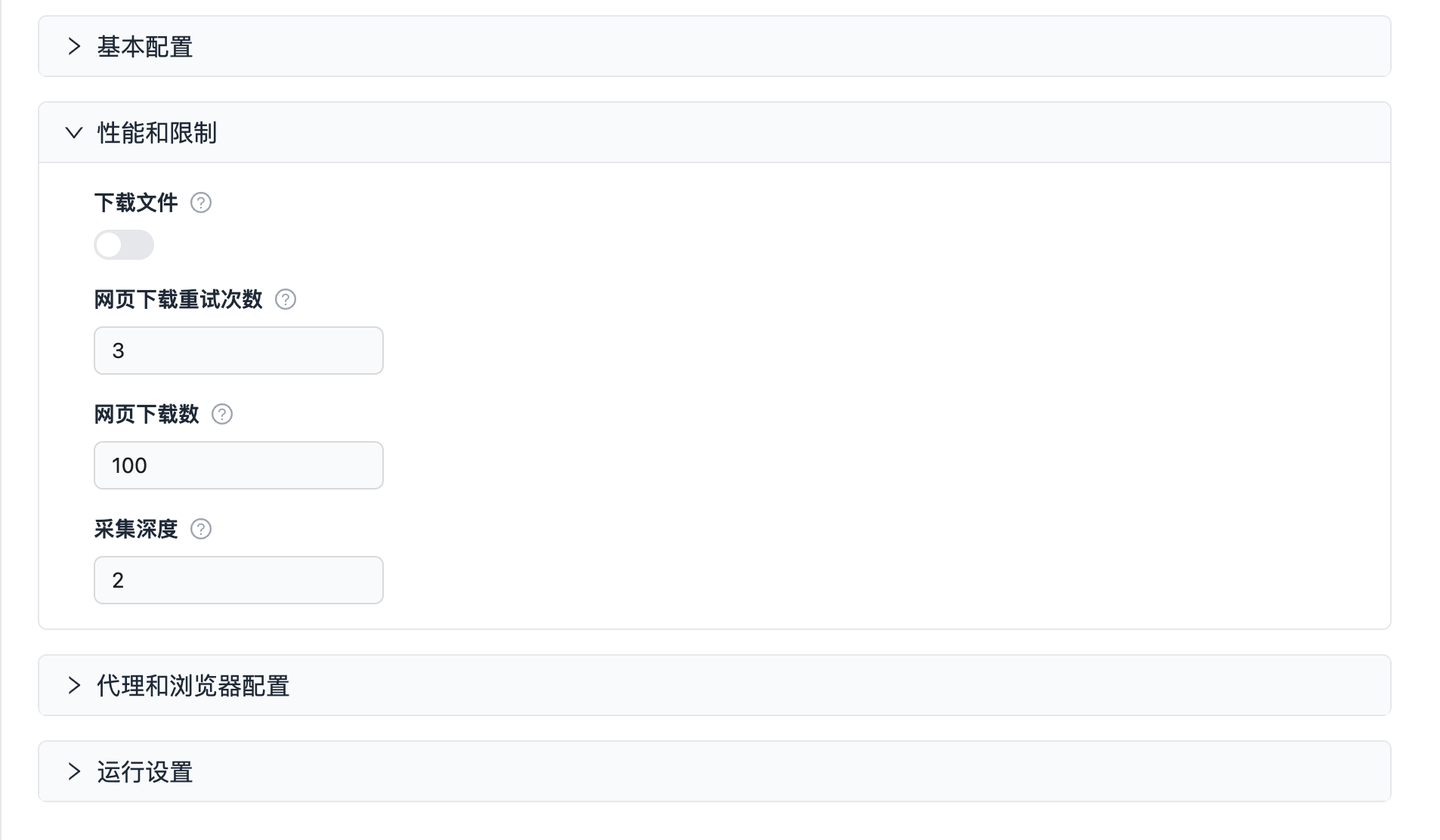 |
| groupCaption | string | 否 | 如果设置了此属性,则此字段后面的所有字段(包括此字段)将被归纳为一个组。 |
字段类型
string类型
输入
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是 string 的配置
"title_xpath": {
"title": "标题提取规则",
"type": "string",
"description": "标题提取规则的功能描述",
"editor": "textfield",
"prefill": "//h1/text()", // 默认值,可选项
"minLength": 3, // 最小长度,可选项
"maxLength": 200, // 最大长度,可选项
"pattern": "[0-9A-z-]" // 正则校验,可选项
},
}
}
python读取
from beeize.scraper import Scraper
scraper = Scraper()
scraper.input.get_string('title_xpath')
输出
'//h1/text()'
效果示例

boolean类型
输入
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是 bool 的配置
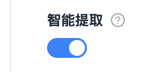
"ai_extract": {
"title": "智能提取",
"type": "boolean",
"description": "启用后不需要提取规则,会自动提取网页的标题、正文、作者、发布时间",
"prefill": true // 默认选中
}
}
}
python读取
scraper.input.get_bool('ai_extract')
输出
True
效果示例
integer 类型
输入
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是 integer 的配置
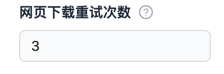
"max_request_retries": {
"title": "网页下载重试次数",
"type": "integer",
"description": "采集器下载网页失败后可进行的最大重试次数",
"minimum": 1, // 可选项,设置最小值
"maxmum": 1, // 可选项,设置最大值
"prefill": 3 // 默认值
}
}
}
python读取
scraper.input.get_int('max_request_retries')
输出
3
效果示例
array类型
输入
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是 array 的配置模板
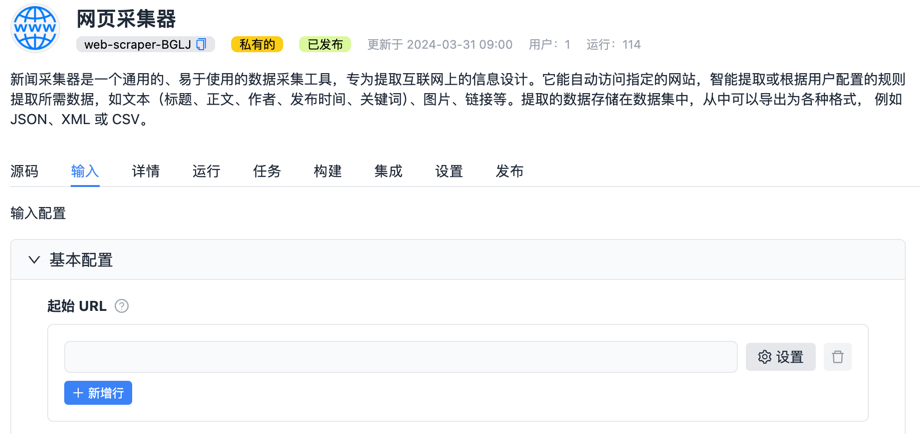
"start_urls": {
"sectionCaption": "基本配置",
"title": "起始 URL",
"type": "array",
"description": "爬虫开始抓取的初始 URL 列表。",
"prefill": [
{
"url": "https://beeize.com"
}
],
"editor": "requestListSources",
"required": true
}
}
}
python读取
scraper.input.get_list('start_urls')
输出
['http://beeize.com']
效果示例
组件
对于有些复杂输入或者特殊样式展示的情况,需要组件的支持。平台目前支持组件如下:
proxy 代理组件
如果想用平台提供的代理,需使用 proxy 组件。平台支持代理,会根据用户的配置选择代理,代码里读取 PROXY_URL 环境变量就能够拿到用户选择的代理。
当前代理只支持在平台内部使用,暂不支持在平台外部使用。
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是代理的配置模板
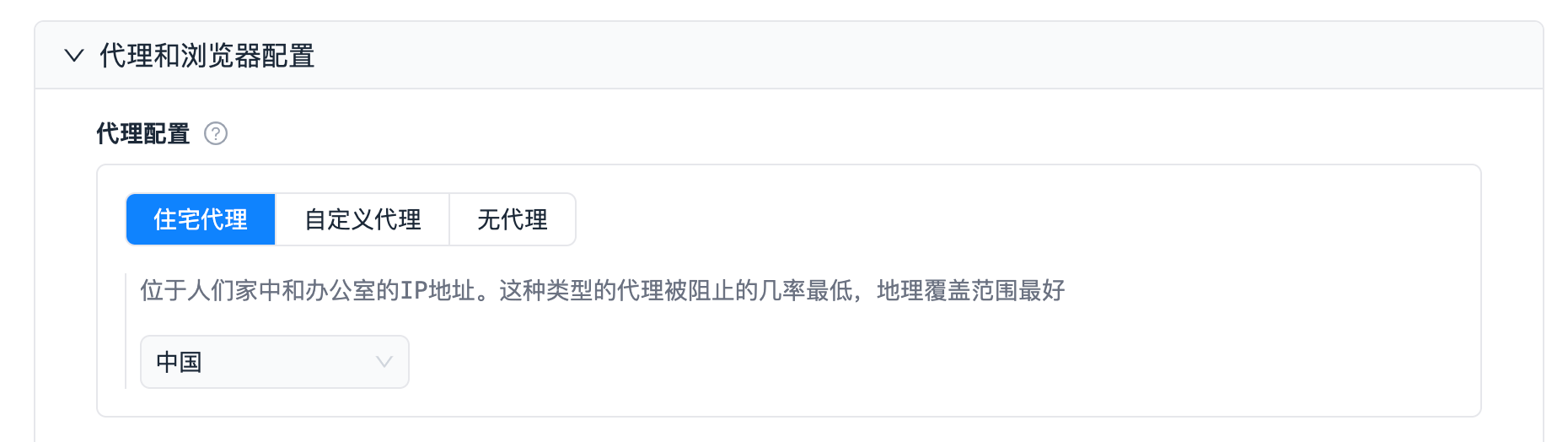
"proxyConfiguration": {
"sectionCaption": "代理和浏览器配置",
"title": "代理配置",
"type": "object",
"description": "采集器使用的代理服务器配置",
"editor": "proxy",
// 默认选择 住宅代理,代理国家为中国,
"prefill": {
"proxyType": "RESIDENTIAL", // 支持 RESIDENTIAL(住宅代理) 、OWN(自定义代理)、NO_PROXY(不使用代理)
"countryCode": "cn"
},
// 如果为 true,则必须使用代理,界面上“无代理”选项将无法选择
"required": true
}
}
}
展现样式
python读取
读取到的 proxy_url 为 http://<用户名>:<密码>@proxy.beeize.com:28000,例如
http://groups-RESIDENTIAL-cn:xxxx@proxy.beeize.com:28000
使用示例:
scraper.input.get_proxies()
['http://<用户名>:<密码>@proxy.beeize.com:28000', 'http://<用户名>:<密码>@proxy.beeize.com:28000']
scraper.input.get_random_proxy()
http://<用户名>:<密码>@proxy.beeize.com:28000
select
下拉组件。
扩展字段
{
"title": "你的应用",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
// 下面是select的配置模板
"run_mod": {
// 传入到采集器的枚举值
"enum": [
"PRODUCTION",
"DEVELOPMENT"
],
// 下拉组件界面展示信息
"enumTitles": [
"生产环境",
"开发环境"
],
"type": "string", // 必须,当前只支持 string 类型的数据选择
"prefill": "DEVELOPMENT",
"editor": "select"
}
}
}
展现样式

requestListSources
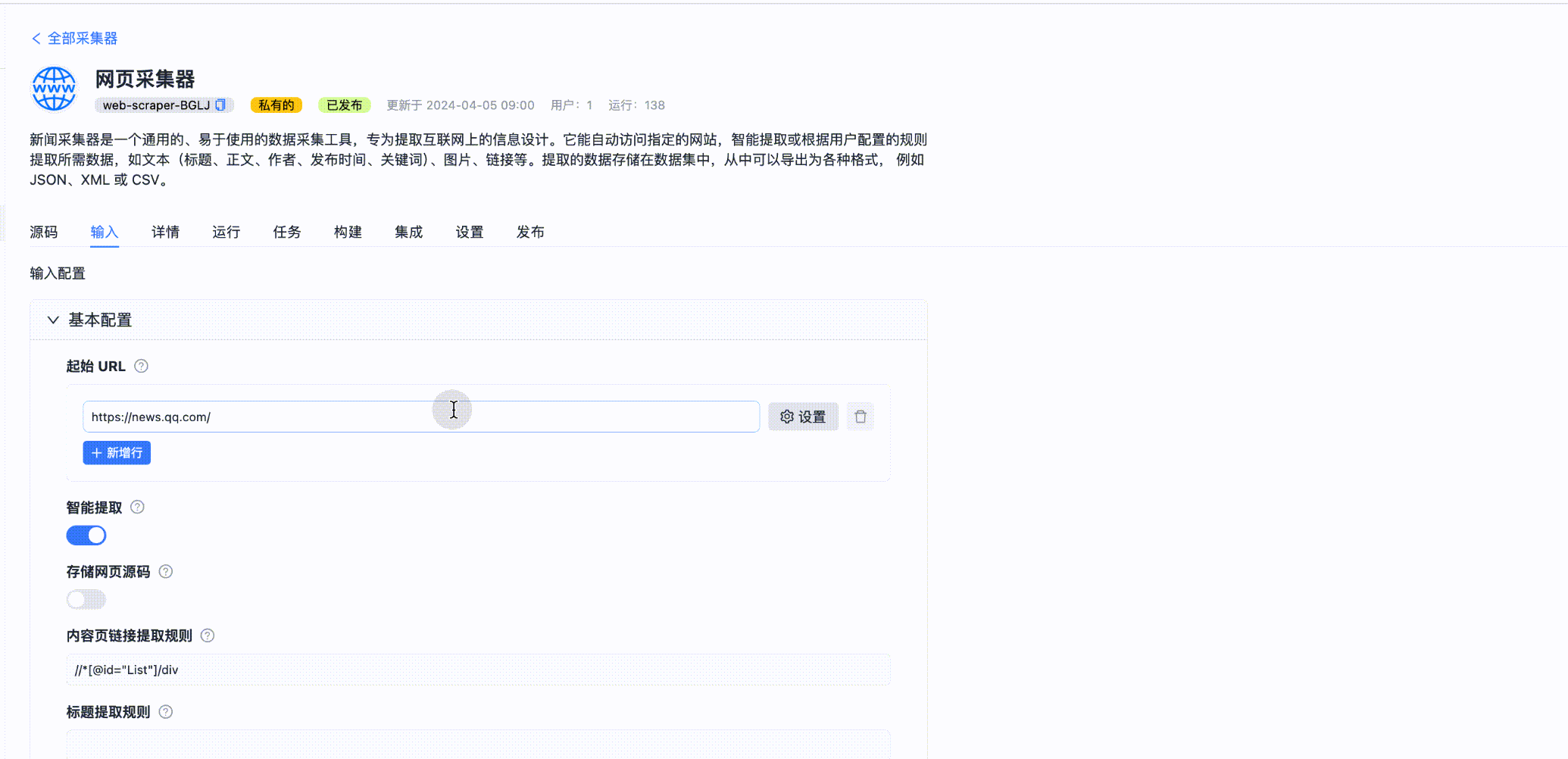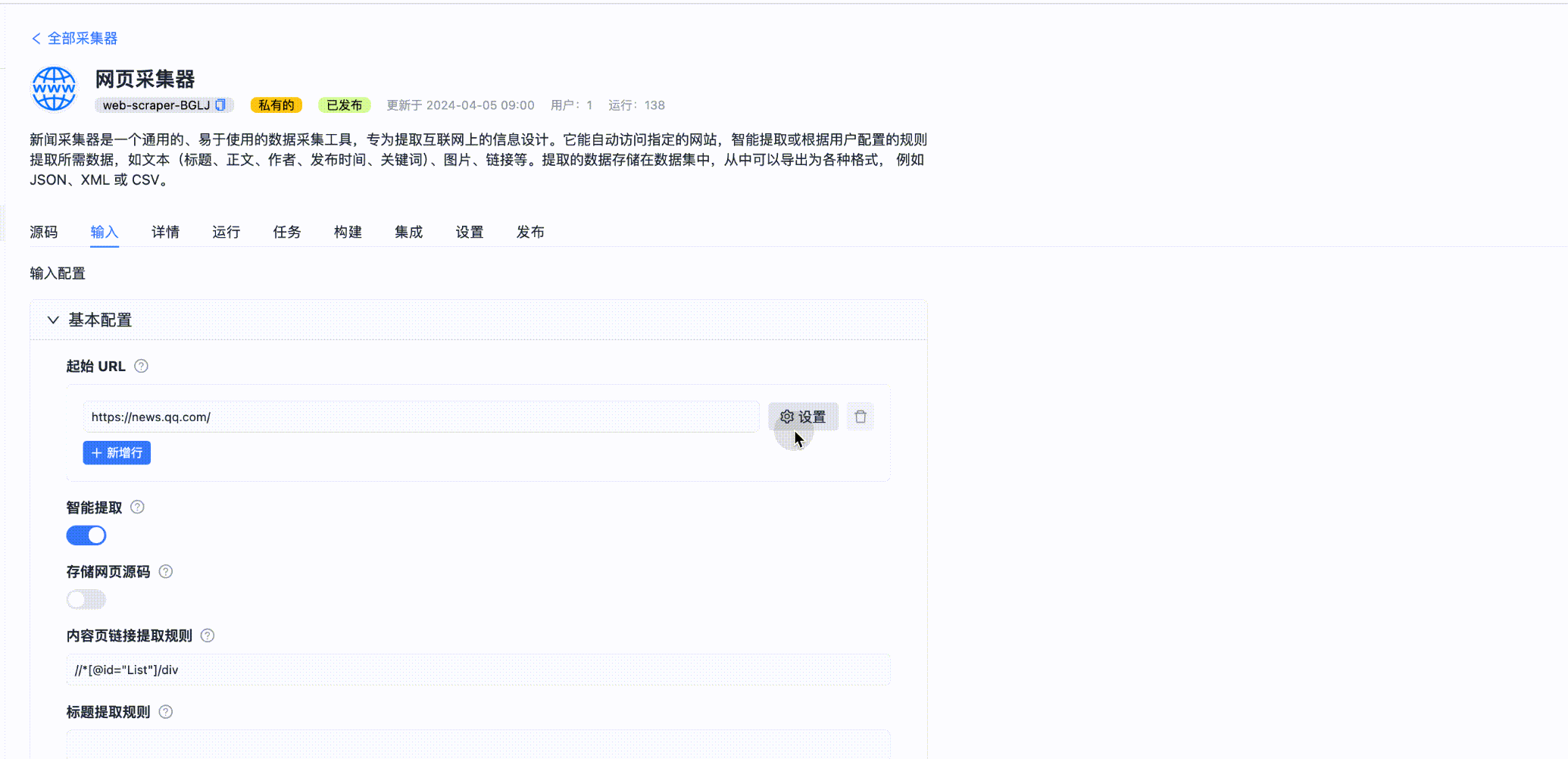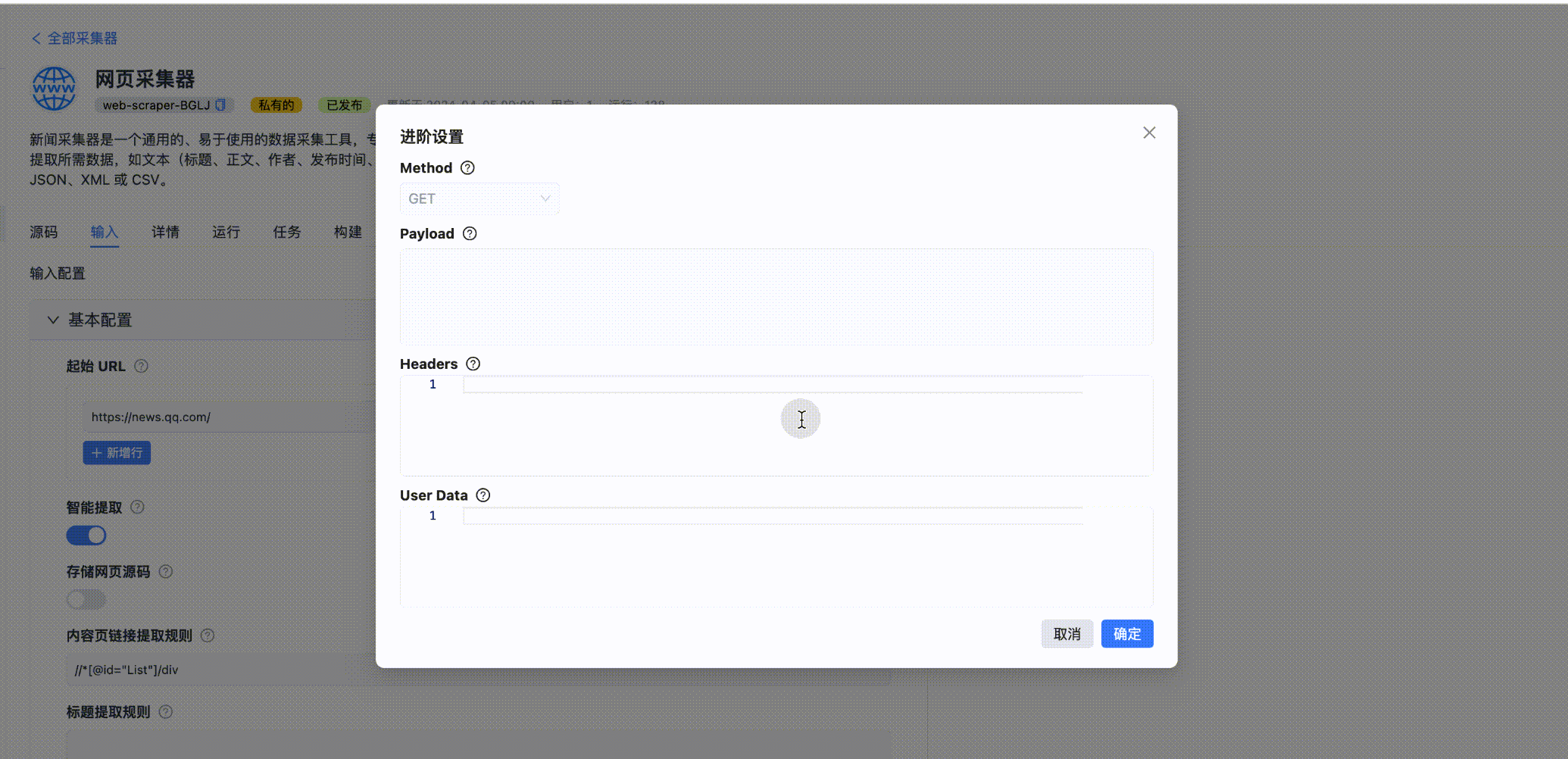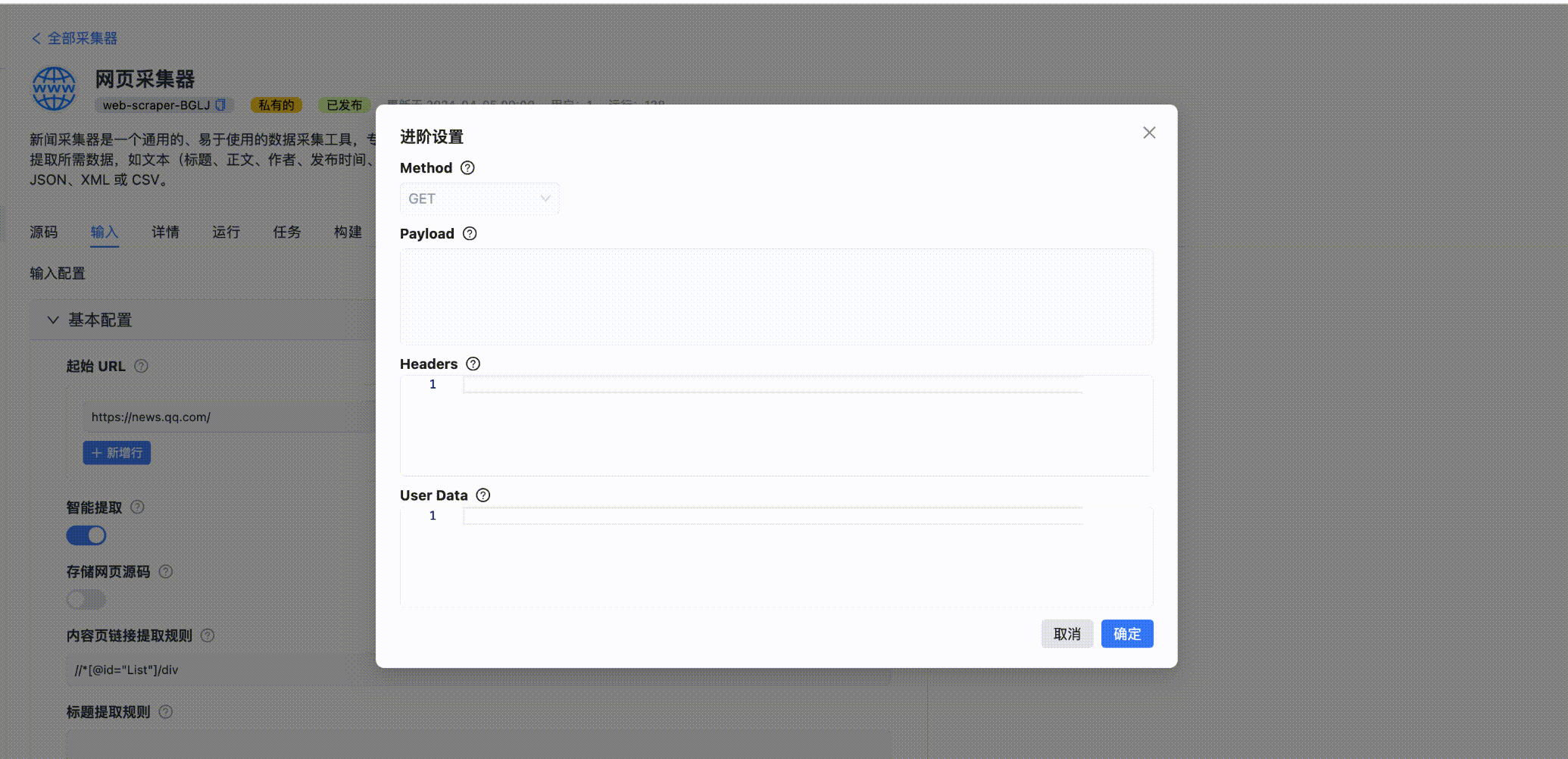
URL 链接列表,可以设置 method、Payload、Headers 以及 User Data。
展现样式
json
json 输入组件。输入的内容会按照 json 样式展示。
展现样式
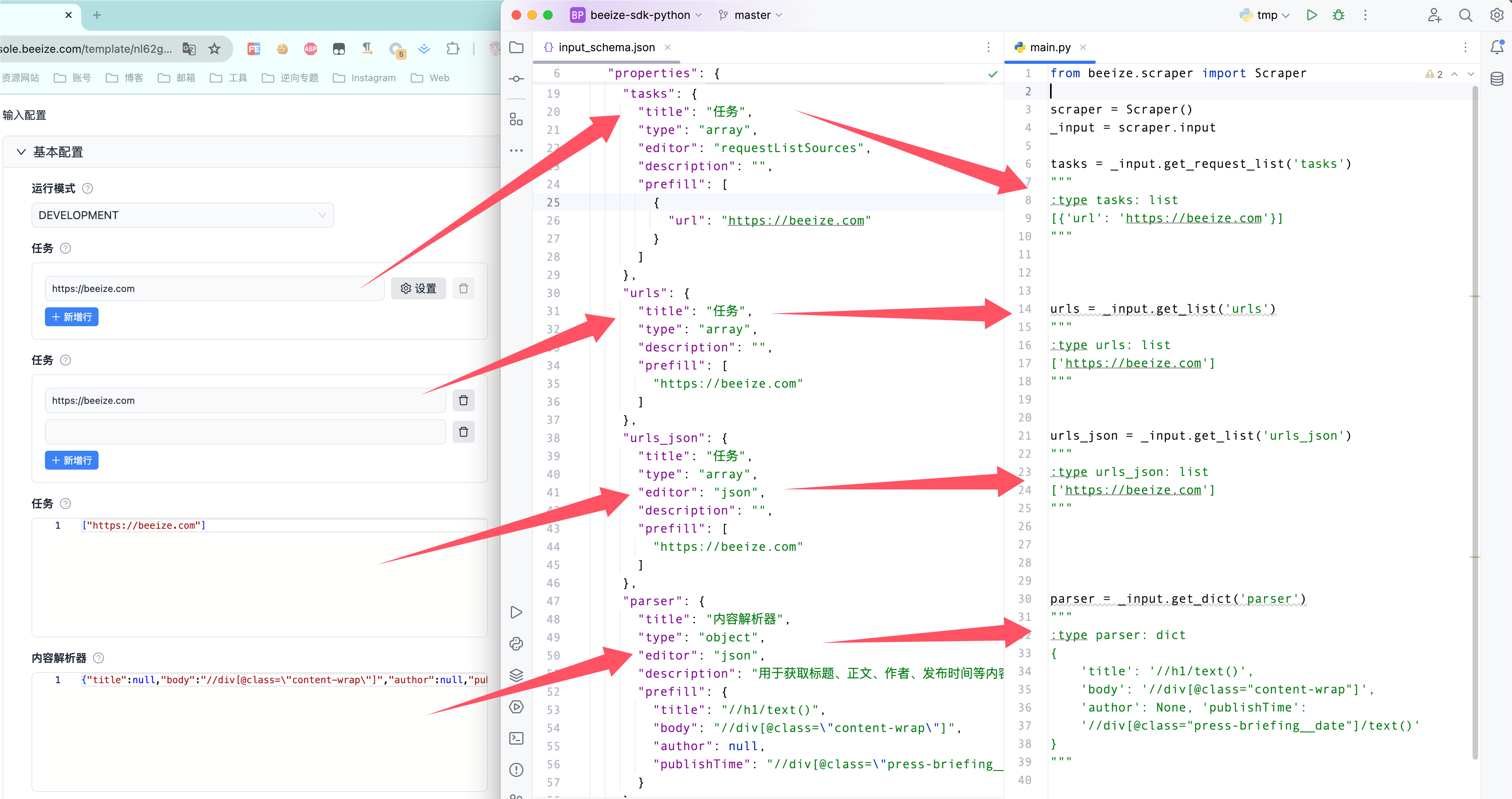
object、list、requestListSources输入读取的区别
array类型的输入框由editor决定
textarea
文本域组件。
扩展字段
{
"title": "你的应用",
"type": "object",
"description": "",
"schemaVersion": 1,
"properties": {
"prompt": {
"title": "Prompt 提示词",
"type": "string",
"description": "大语言模型的提示词,跟其他采集器集成,可以添加变量 {{字段名称}}",
"prefill": "下面是一篇文章,请提取文章的摘要,不超过100个字:\n文章标题为:{{ diversion_control_v2.title }}\n\n文章内容为:\n{{ content }}",
"editor": "textarea",
"required": true
}
}
}
展现样式

参考示例
input_schema.json
{
"title": "网页采集器",
"type": "object",
"description": "输入配置",
"schemaVersion": 1,
"properties": {
"start_urls": {
"sectionCaption": "基本配置",
"title": "起始 URL",
"type": "array",
"description": "爬虫开始抓取的初始 URL 列表。",
"prefill": [
{
"url": "http://www.news.cn/auto/index.html"
}
],
"editor": "requestListSources",
"required": true
},
"ai_extract": {
"title": "智能提取",
"type": "boolean",
"description": "启用后不需要提取规则,会自动提取网页的标题、正文、作者、发布时间",
"prefill": true
},
"body_html": {
"title": "存储网页源码",
"type": "boolean",
"description": "启用后存储所有内容页的网页源代码",
"prefill": false
},
"detail_link_extract": {
"title": "内容页链接提取规则",
"type": "string",
"description": "输入获取列表页一块区域的 xpath 选择器,用于采集详情页",
"editor": "textfield",
"prefill": null
},
"title_extract": {
"title": "标题提取规则",
"type": "string",
"description": "用于获取标题的 xpath 选择器",
"editor": "textfield",
"prefill": null
},
"body_extract": {
"title": "正文提取规则",
"type": "string",
"description": "用于获取正文的 xpath 选择器",
"editor": "textfield",
"prefill": null
},
"author_extract": {
"title": "作者提取规则",
"type": "string",
"description": "用于获取作者的 xpath 选择器",
"editor": "textfield",
"prefill": null
},
"publish_time_extract": {
"title": "发布时间提取规则",
"type": "string",
"description": "用于获取发布时间的 xpath 选择器",
"editor": "textfield",
"prefill": null
},
"page_link_extract": {
"title": "获取下一页链接的提取规则",
"type": "string",
"description": "输入获取下一页链接的 xpath 选择器,用于翻页采集",
"editor": "textfield",
"prefill": null
},
"download_media": {
"sectionCaption": "性能和限制",
"title": "下载文件",
"type": "boolean",
"description": "启用后,爬虫将下载网页上的文件。",
"default": true
},
"max_request_retries": {
"title": "网页下载重试次数",
"type": "integer",
"description": "采集器下载网页失败后可进行的最大重试次数",
"minimum": 1,
"prefill": 3
},
"max_downloads_limit": {
"title": "网页下载数",
"type": "integer",
"description": "限制采集器在单次运行中最多下载多少网页",
"minimum": 1,
"prefill": 100
},
"max_crawling_depth": {
"title": "采集深度",
"type": "integer",
"description": "采集器在网页链接结构中递归遍历的层数",
"minimum": 1,
"prefill": 2
},
"proxyConfiguration": {
"sectionCaption": "代理和浏览器配置",
"title": "代理配置",
"type": "object",
"description": "采集器使用的代理服务器配置",
"editor": "proxy",
"prefill": null,
"required": true
},
"use_chrome": {
"title": "使用 Chrome",
"type": "boolean",
"description": "启用后可下载动态加载数据的网页",
"prefill": false
}
}
}