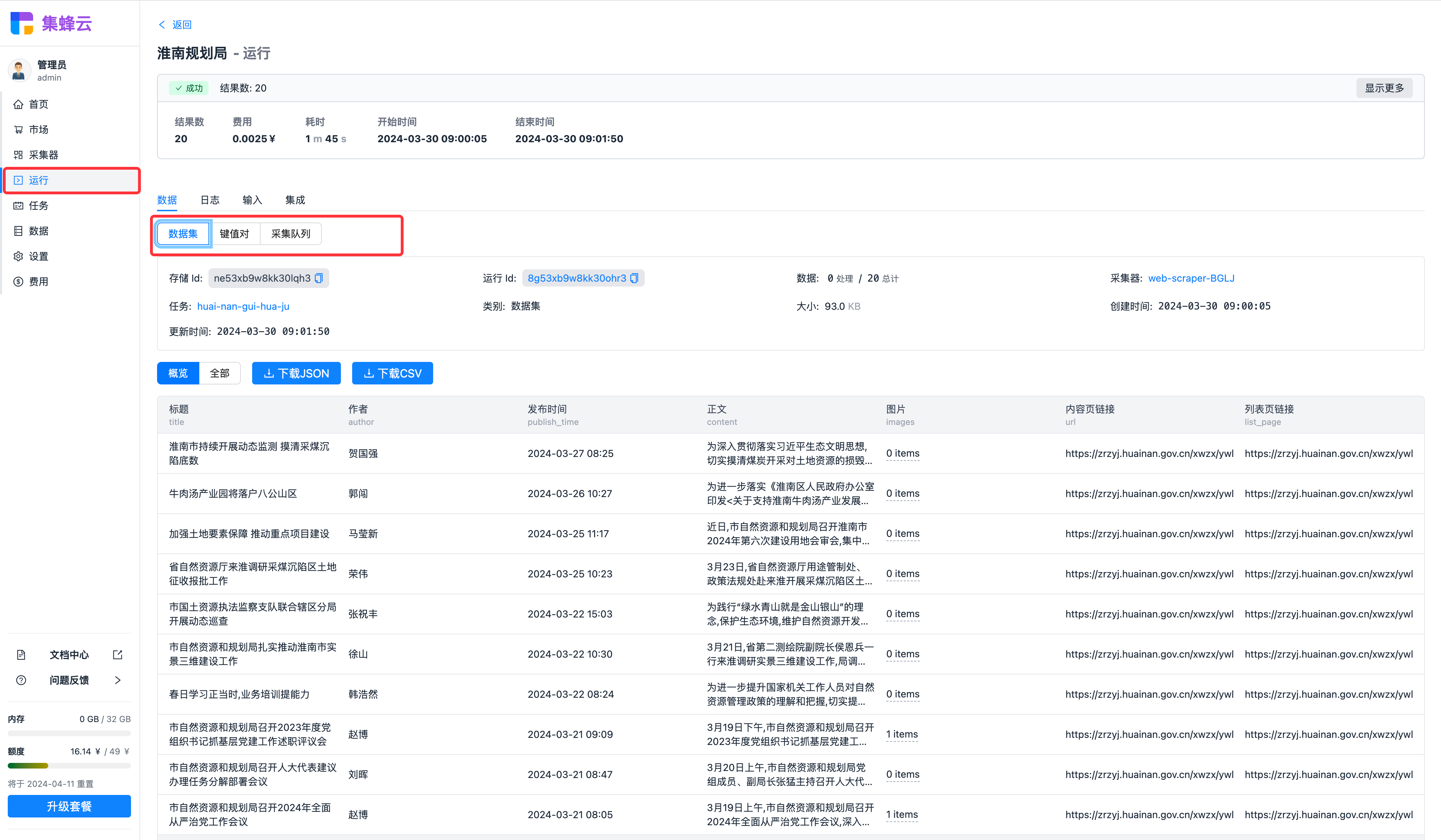
输入与输出
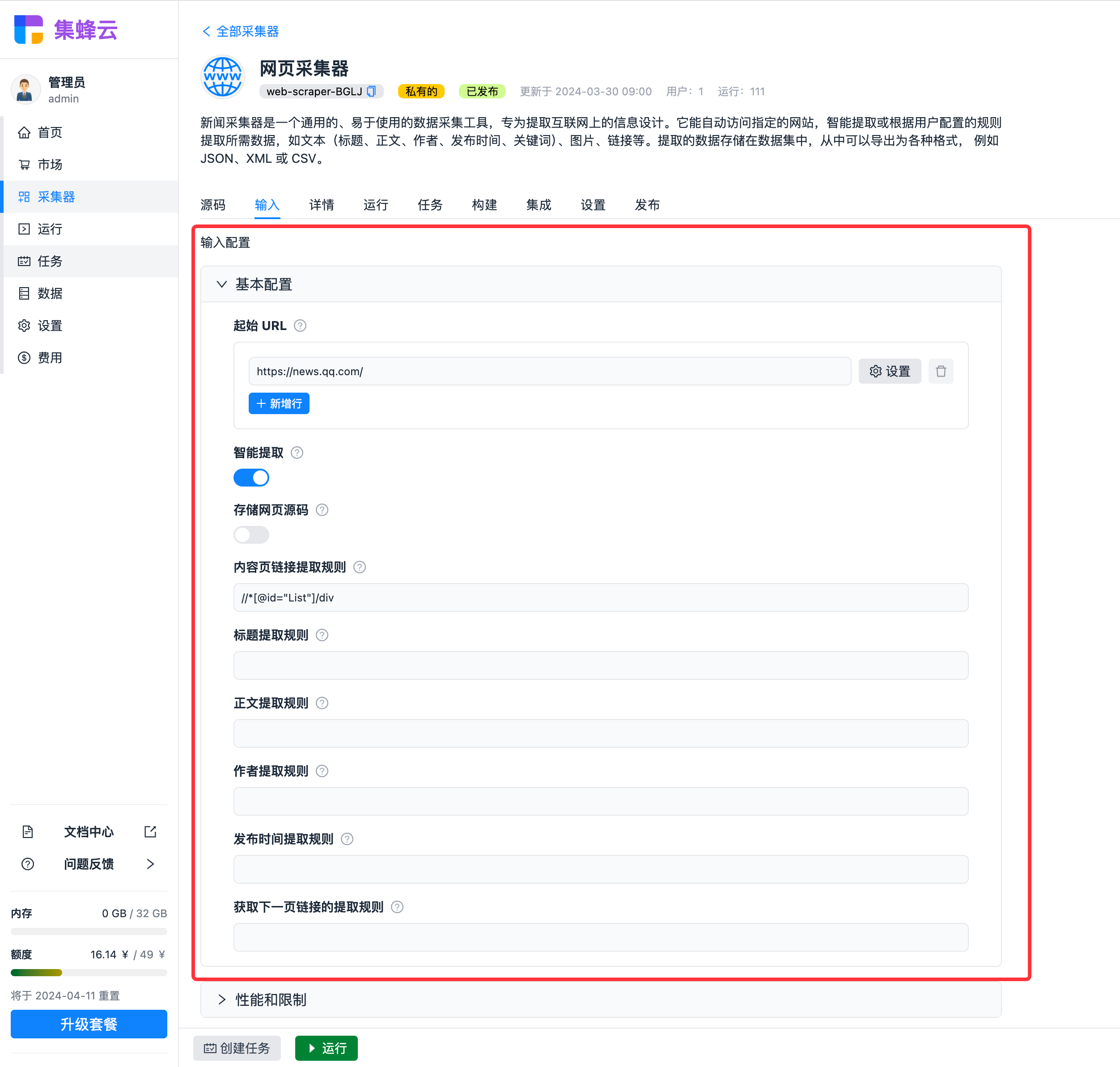
输入
每个采集器都提供了一些输入选项,定义它的行为。您可以通过界面进行配置,也可以通过 API 传入相同的 JSON 来启动采集器。
每个输入的字段,可以在详情界面找到说明。
运行设置
每个采集器都可以对运行环境进行配置,包括标签、超时时间、和内存。
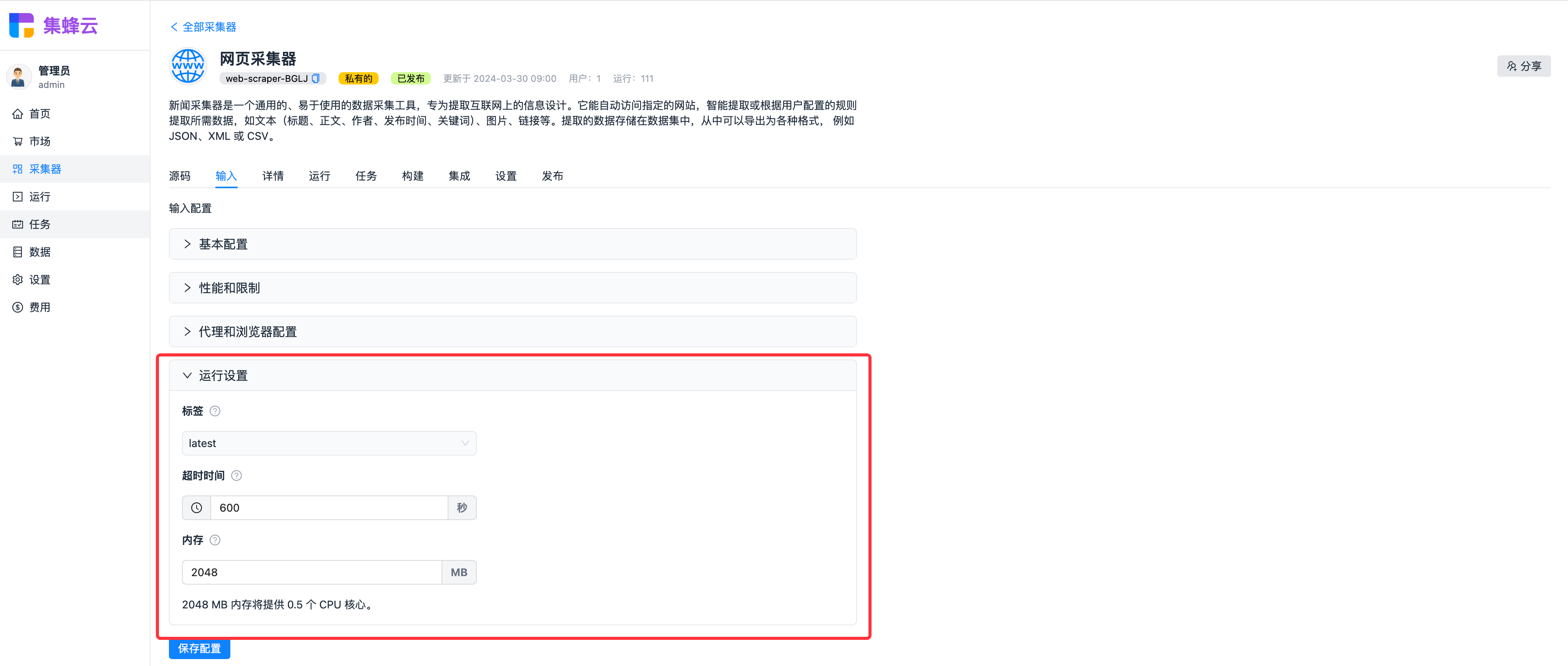
标签
开发者可以给构建的程序打上不同的标签(有点类似于代码的分支),通常标签为 latest、prod、dev 或者一些大的版本号。 通过选择对应的标签,每次运行时,会自动获取该标签下最新构建的程序。
标签
采集器运行的超时时间。运行超过该时间时,运行会强制停止,避免由于程序异常等情况导致费用增加。 建议设置合理的超时时间。
内存
采集器运行时的内存大小。系统按照 4:1 的比例分配采集器运行时内存与 cpu。内存越大,cpu 分配的越多,运行速度也会越快。 但内存越大,单位时间消耗的计算单元(1个计算单元为 1G 内存运行 1 小时)就会越多。
输出
采集器采集到的数据可以在数据中查看。数据分为三类,分别是数据集、键值对以及采集队列。
| 存储类型 | 描述 |
|---|---|
| 数据集 | 采集的结果数据,通常是 JSON 形式。可以导出 JSON 或者 CSV。 |
| 键值对 | 键值存储可用于存储任何类型的数据。它可以是 JSON 或文件、图片、视频、压缩包等。 |
| 采集队列 | 存储采集的 URL 信息,并记录每个 URL 的处理情况。 |
采集到的数据只保留 7 天,过期将会删除。采集完成后请尽快取回。