SDK
平台目前提供 Python SDK,方便开发者接入到平台。它提供了读取用户输入、数据存储等实用功能。
安装
pip install beeize-sdk-python
初始化
from beeize.scraper import Scraper
scraper = Scraper()
scraper 要为全局变量,进程唯一。
读取输入
示例:
from beeize.scraper import Scraper
scraper = Scraper()
_input = scraper.input
urls = _input.get_list('urls') # 获取 urls 输入
"""
:type urls: list
['https://beeize.com']
"""
界面、input_schema.json 与 sdk 方法映射表:
| 输入类型 | input_schema 的 properties 字段定义 | 界面样式 | sdk 读取方式 |
|---|---|---|---|
| string |  |
 |
_input.get_string('linkSelector')返回 string 类型 |
| bool | 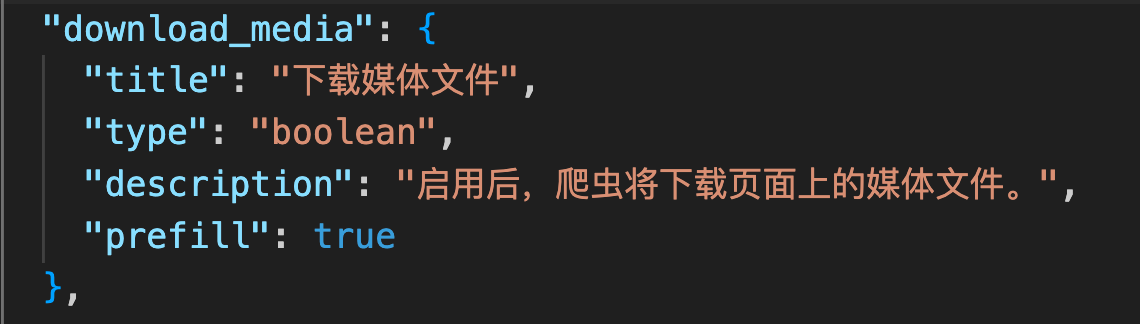 |
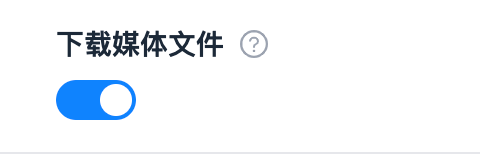 |
_input.get_bool('download_media')返回 bool 类型 |
| int |  |
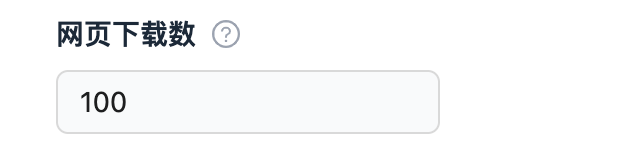 |
_input.get_int('max_downloads_limit')返回 int 类型 |
| float | |
|
_input.get_float('max_downloads_limit')返回 float 类型 |
| list |  |
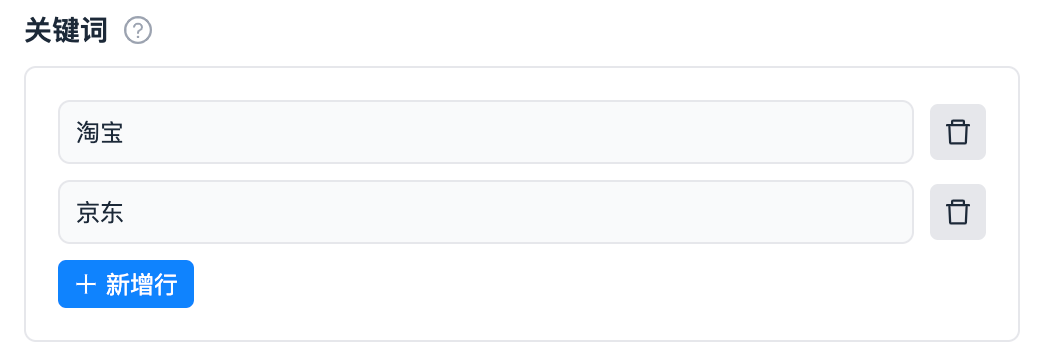 |
_input.get_list('keywords')返回 list 类型 |
| object |  |
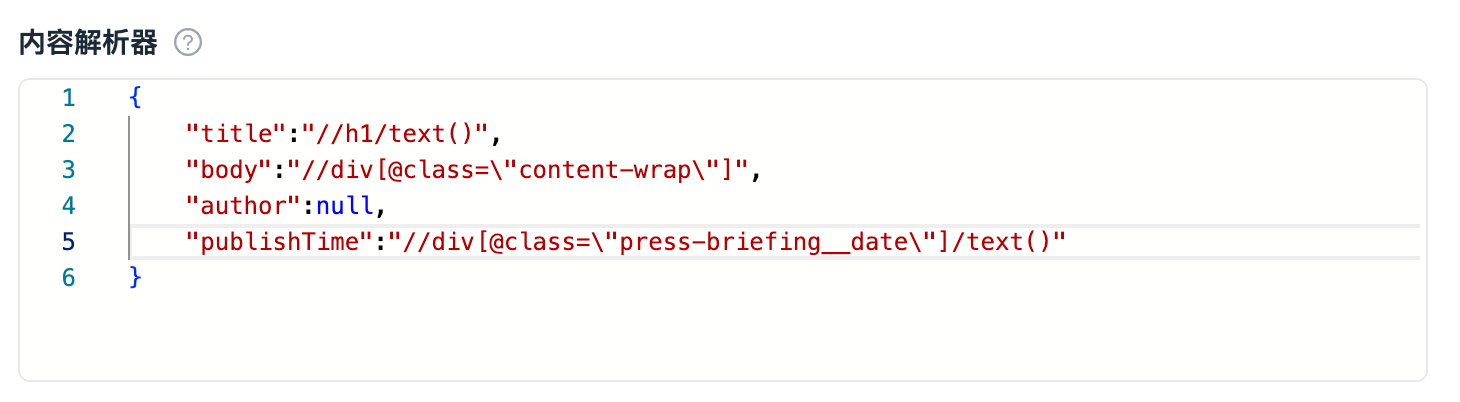 |
_input.get_dict('keywords')返回 dict 类型 |
| json | 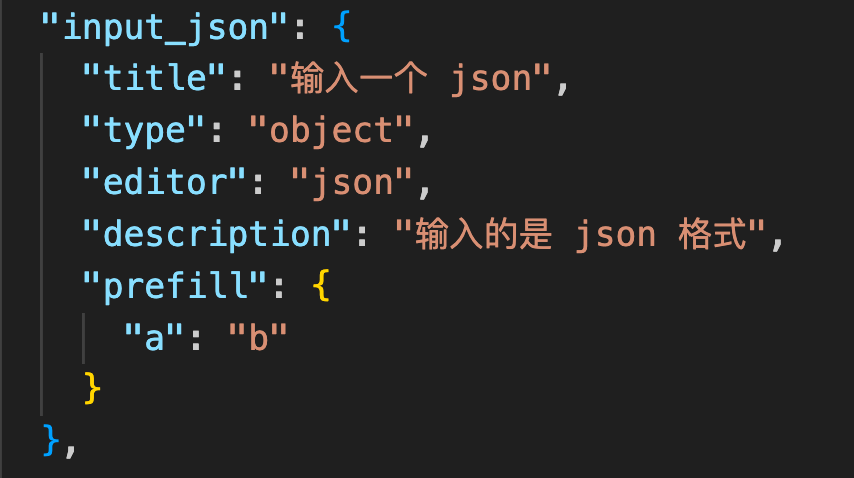 |
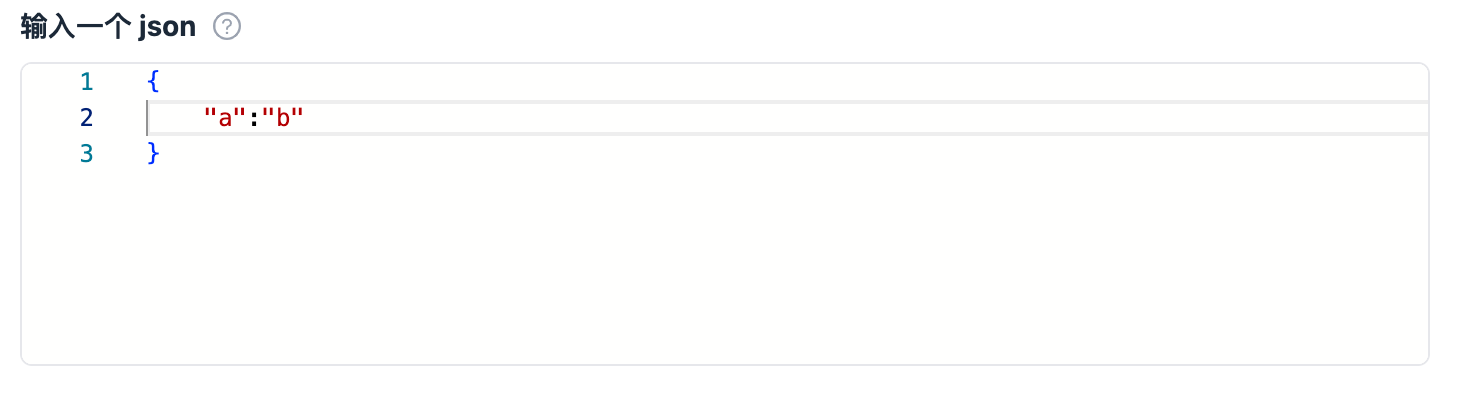 |
_input.get_dict('input_json')返回 dict 类型 |
| enum |  |
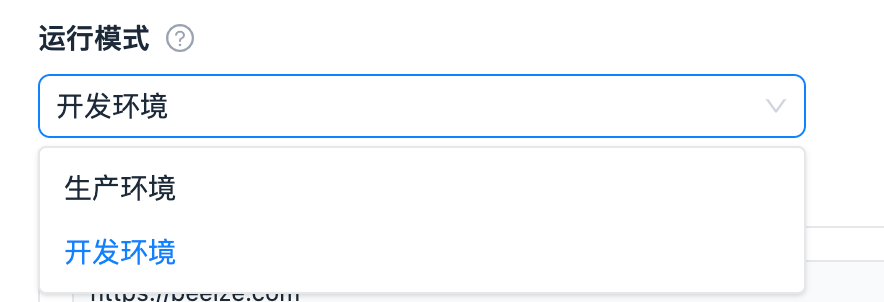 |
_input.get_string('runMode')返回 string 类型 |
| requestListSources | 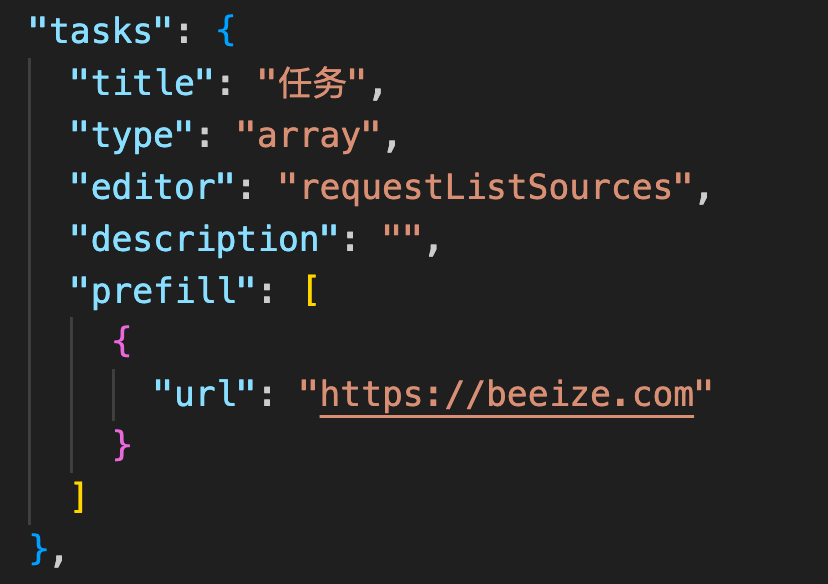 |
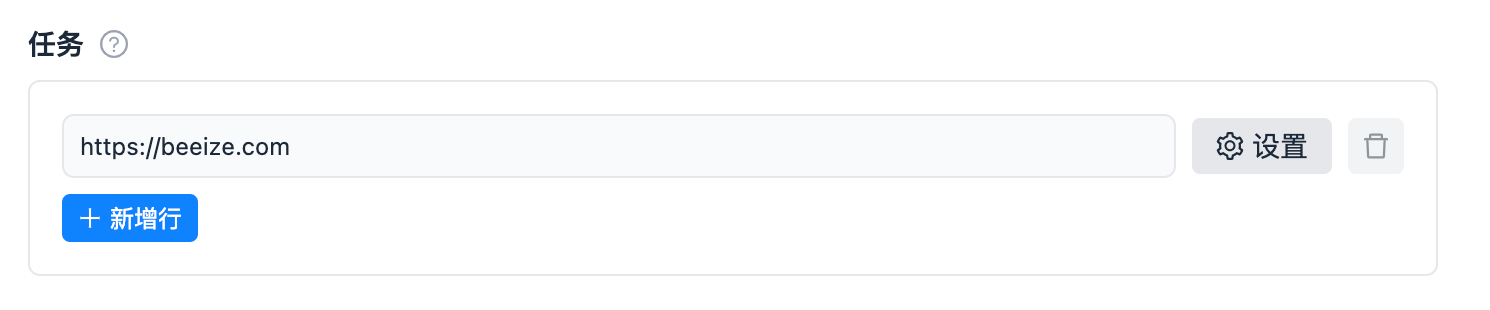 |
_input.get_request_list('tasks')返回 list<dict> 类型 |
| 代理 |  |
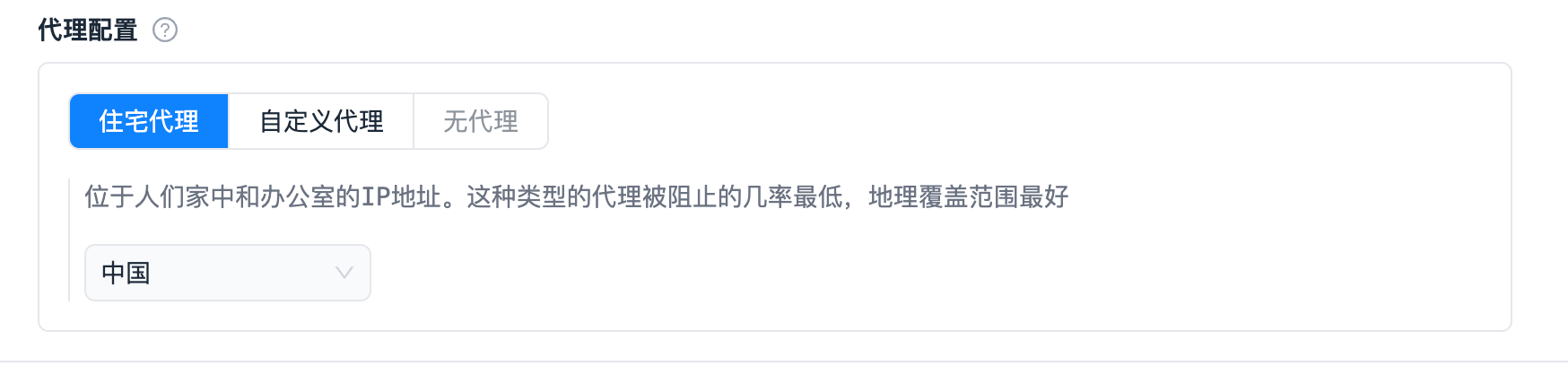 |
_input.get_proxies()返回所有输入的代理,list<string> 类型,返回None则没有设置代理。 _input.get_random_proxy()随机一个代理,返回 string 类型, 返回None则没有设置代理。 |
输出
写入到数据集
from beeize.scraper import Scraper
scraper = Scraper()
item = {
'url': "https://beeize.com",
'type': 'complete'
}
scraper.push_data(item)
push_data 方法是线程安全的。
写入到键值对
from beeize.scraper import Scraper
scraper = Scraper()
# 存储一个 json
key_value_store = scraper.key_value_store
key_value_store.set_value("json_file_name", {"name": "jack"})
# 存储一个文件,比如图片、视频等
demo_image = open('demo.jpg', 'rb').read()
key_value_store.set_value(
key="demo",
value=demo_image,
extension='jpg'
)
file = key_value_store.get_value("a") # 读取
set_value 方法是线程安全的。
写入到采集队列
from beeize.scraper import Scraper
scraper = Scraper()
request_queue = scraper.request_queue
# 添加一个请求到采集队列
request = request_queue.add_request(
{"url": "https://baidu.com"}
)
print(request) # 打印 {'url': 'https://baidu.com', 'uniqueKey': 'https://baidu.com', 'requestId': 'V9zL2HW7G3RVIIo'}
# 消费队列中的请求任务
while request_queue.is_finished():
# 取任务
request = request_queue.fetch_next_request()
url = request['url']
response = fetch_url(url) # 请求 url
if not response:
# 对失败请求进行标记
request_queue.reclaim_request(request)
continue
# 对成功请求进行标记
request_queue.mark_request_as_handled(request)
根据 requestId 获取 request
# 添加一个请求到采集队列
request = request_queue.add_request(
{"url": "https://baidu.com"}
)
print(request) # 打印 {'url': 'https://baidu.com', 'uniqueKey': 'https://baidu.com', 'requestId': 'V9zL2HW7G3RVIIo'}
request = request_queue.get_request(request['requestId'])
print(request) # 打印 {'url': 'https://baidu.com', 'uniqueKey': 'https://baidu.com', 'requestId': 'V9zL2HW7G3RVIIo'}
获取用户是否付费
对于按结果数收费的采集器,免费用户试用不再给开发者分成,建议开发者可以根据用户付费情况采取不同策略,并在日志中建议用户升级套餐,升级套餐的地址为:https://console.beeize.com/billing?tab=price。
from beeize.scraper import Scraper
scraper = Scraper()
_input = scraper.input
is_free = _input.is_free_user()
"""
:type is_free: bool
True: 免费用户
Flase: 付费用户
"""