前程无忧职位信息如何高效采集?三种实用方法分享
如何高效采集前程无忧职位信息?三大实战策略揭秘
摘要
本文旨在探讨高效获取前程无忧网站职位信息的实用方法,帮助HR与数据分析人员快速洞悉市场动态,优化招聘策略。通过深入浅出的教程,揭示自动化采集的奥秘,提升工作效率。
关键词
- 前程无忧
- 职位信息采集
- 数据抓取
- 高效工具
- 实战策略
引言:信息时代下的招聘挑战
在信息爆炸的时代,企业人力资源部门面临着前所未有的挑战——如何从海量招聘信息中精准定位目标人才。前程无忧作为国内领先的招聘平台,其丰富的职位信息成为了众多企业和猎头眼中的“金矿”。然而,手动筛选不仅耗时耗力,还可能错失良机。因此,掌握高效采集前程无忧职位信息的方法显得尤为重要。
一、利用RSS订阅(Really Simple Syndication)
关键词融入:前程无忧, 职位信息
对于追踪特定岗位或行业动态的需求,RSS订阅是入门级但高效的选择。前程无忧支持RSS输出,用户只需将感兴趣的职位搜索结果页面的RSS链接添加到RSS阅读器中,即可自动接收新发布的职位信息。
操作指南:
- 搜索定位:在前程无忧网站上,输入目标职位关键词进行搜索。
- 获取RSS:在搜索结果页面,找到并复制RSS订阅链接。
- 添加订阅:使用RSS阅读器(如Feedly)粘贴链接并添加订阅。
优点:操作简单,实时更新,无需编程知识。
二、Web Scraping技术浅析
关键词融入:数据抓取, 高效工具
Web Scraping(网页抓取)是一种自动化采集网页数据的技术,适用于大规模数据需求。通过编写简单的脚本,可以定制化地抓取前程无忧上的职位列表、详情页等信息。
技术选型:
- Python + BeautifulSoup:Python因其易学性成为初学者首选,而BeautifulSoup库能轻松解析HTML文档,提取所需数据。
- Selenium:对于动态加载的内容,Selenium提供了模拟浏览器操作的能力,可处理JavaScript渲染的页面。
实践步骤:
- 环境搭建:安装Python环境,通过pip安装所需的库。
- 分析页面结构:使用浏览器开发者工具查看网页源代码,确定数据所在标签。
- 编写脚本:根据分析结果,编写代码实现数据抓取逻辑。
- 运行与调试:执行脚本,根据实际情况调整逻辑直至数据正确抓取。
注意:在进行Web Scraping时,务必遵守网站的robots.txt规则,尊重数据版权,避免频繁请求导致IP被封。
三、借助专业数据采集服务
关键词融入:高效工具
当个性化需求复杂或技术门槛较高时,选择第三方数据采集服务成为明智之举。这类服务通常提供图形界面操作,简化配置过程,同时保障数据的准确性和稳定性。
推荐方案:集蜂云平台提供了从任务创建到数据交付的一站式解决方案,其海量任务调度、三方应用集成以及监控告警等功能,尤其适合企业级用户高效、稳定地采集前程无忧等网站数据。
优势总结:
- 零编程:用户友好界面,无需编程基础。
- 高灵活性:支持多种数据源,高度自定义抓取规则。
- 稳定高效:云端服务,自动处理异常,确保数据连续性。
常见问题解答
-
Q: 使用Web Scraping是否合法? A: 在不违反网站政策和相关法律法规的前提下,合理范围内的数据抓取是被允许的。建议仔细阅读目标网站的
robots.txt文件。 -
Q: 如何避免被网站封IP? A: 采取IP代理轮换、设置合理的请求间隔时间、遵循网站爬虫协议等措施可以有效降低被封风险。
-
Q: 数据采集后如何存储和分析? A: 可以选择数据库(如MySQL、MongoDB)存储数据,使用Excel、Tableau或Python的Pandas库进行初步数据分析。
-
Q: 自动化采集需要多长时间学习? A: 对于基本的Web Scraping,掌握Python基础和相关库,大约一周时间即可上手。
-
Q: 集蜂云平台相比自建爬虫有何优势? A: 集蜂云平台提供一站式服务,免去了自行维护服务器、处理异常的麻烦,特别适合需要快速部署和持续数据流的企业用户。
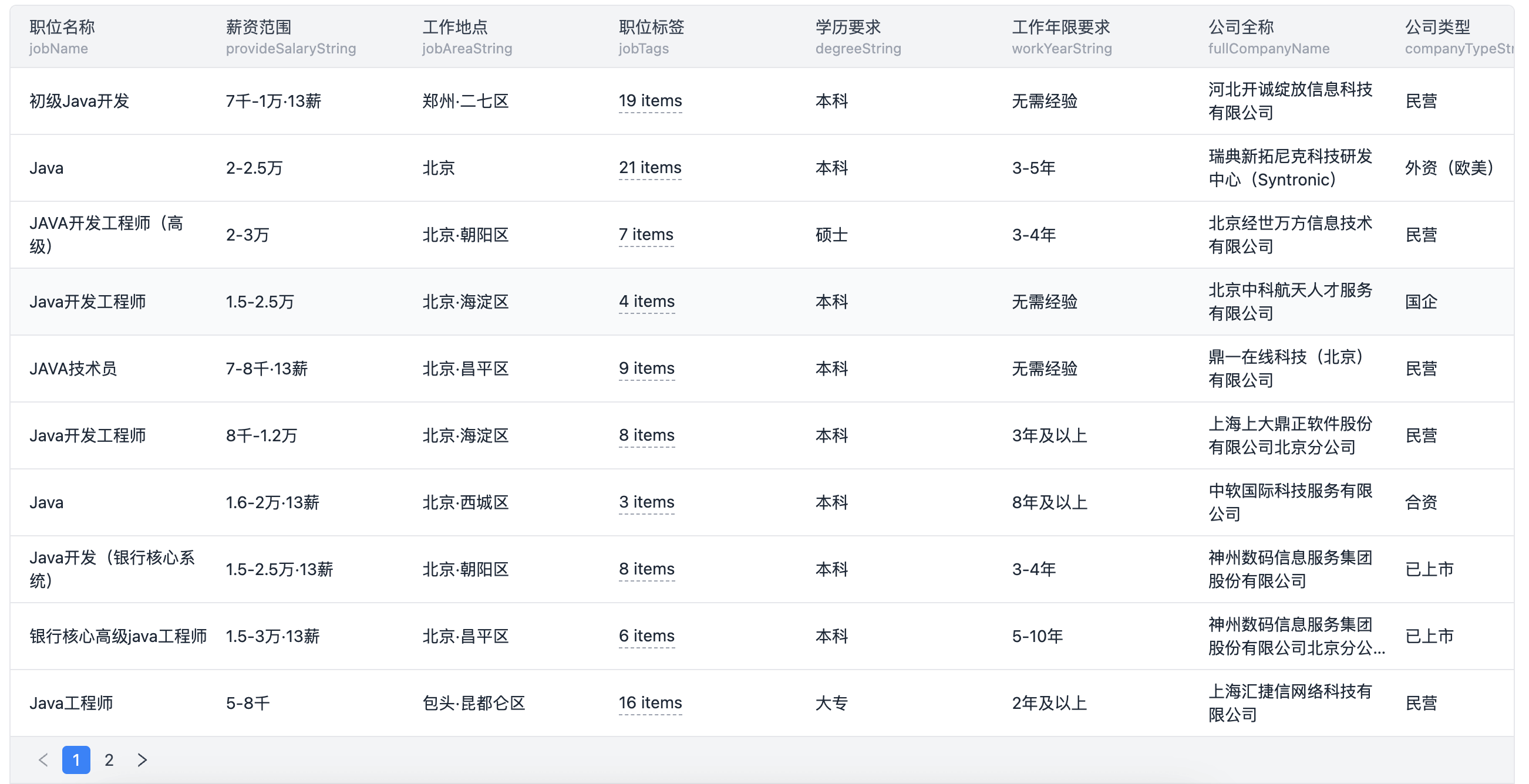
通过上述策略的学习与实践,无论是个人还是企业,都能在信息海洋中更加高效地挖掘前程无忧的职位宝藏,为人才战略决策提供坚实的数据支撑。