前程无忧招聘数据采集实战:教你利用爬虫技术高效抓取岗位详情
如何高效抓取岗位信息?前程无忧招聘数据实战揭秘!
摘要
在竞争激烈的招聘市场,精准快速地获取岗位信息成为企业与求职者的共同诉求。本文将带你深入了解如何运用爬虫技术,从前程无忧网站高效抓取岗位详情,解锁大数据时代的人才搜索秘籍。通过实战演练,你将掌握一套实用技能,为你的招聘策略或职业规划增添利器。
关键词
- 前程无忧招聘
- 数据采集
- 爬虫技术
- 岗位详情
- 高效抓取
正文
一、为何选择爬虫技术采集招聘数据?
在信息爆炸的今天,手动筛选海量岗位信息既耗时又低效。爬虫技术,作为一种自动化数据抓取手段,能快速准确地从指定网站(如前程无忧招聘)收集所需数据,助你在求职或招聘路上快人一步。
1.1 提升效率
与人工搜索相比,爬虫能在短时间内遍历数以万计的网页,高效提取岗位标题、要求、薪资范围等关键信息。
1.2 数据精准
定制化爬虫可按需抓取特定类型或区域的岗位,确保数据的针对性和准确性。
二、实战准备:技术工具箱揭秘
开始数据采集之前,你需要搭建一个基本的爬虫环境。Python因其丰富的库支持(如requests、BeautifulSoup或Scrapy),成为初学者的首选语言。
2.1 环境搭建
- 安装Python: 确保Python环境已就绪。
- 安装依赖库: 通过pip安装必要的数据抓取库。
2.2 编写基础爬虫
- 请求发送: 使用
requests库发送HTTP请求获取网页内容。 - 解析数据: 利用
BeautifulSoup解析HTML,提取所需信息。
三、实战演练:从前程无忧抓取岗位详情
3.1 分析目标网站结构
首先,分析前程无忧的网页结构,确定哪些信息是我们需要的,比如岗位标题、公司名称、工作地点、薪资范围等。
3.2 编码实现
编写代码,模拟浏览器访问前程无忧的岗位列表页,随后逐条抓取并解析每个岗位详情页面。
import requests
from bs4 import BeautifulSoup
def fetch_job_details(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 根据实际HTML结构调整以下选择器
title = soup.find('h1', class_='job-name').text
company = soup.find('div', class_='company').text.strip()
location = soup.find('span', class_='location').text
salary = soup.find('span', class_='salary').text
return {'title': title, 'company': company, 'location': location, 'salary': salary}
# 示例URL请替换为实际岗位详情页URL
job_url = 'https://www.51job.com/position/xxxxxx.html'
details = fetch_job_details(job_url)
print(details)
四、进阶技巧:处理反爬与规模化采集
随着采集需求的增长,简单的脚本可能遭遇反爬机制。这时,加入代理IP池、设置合理的请求间隔、模拟用户行为等策略变得尤为重要。
五、数据处理与分析
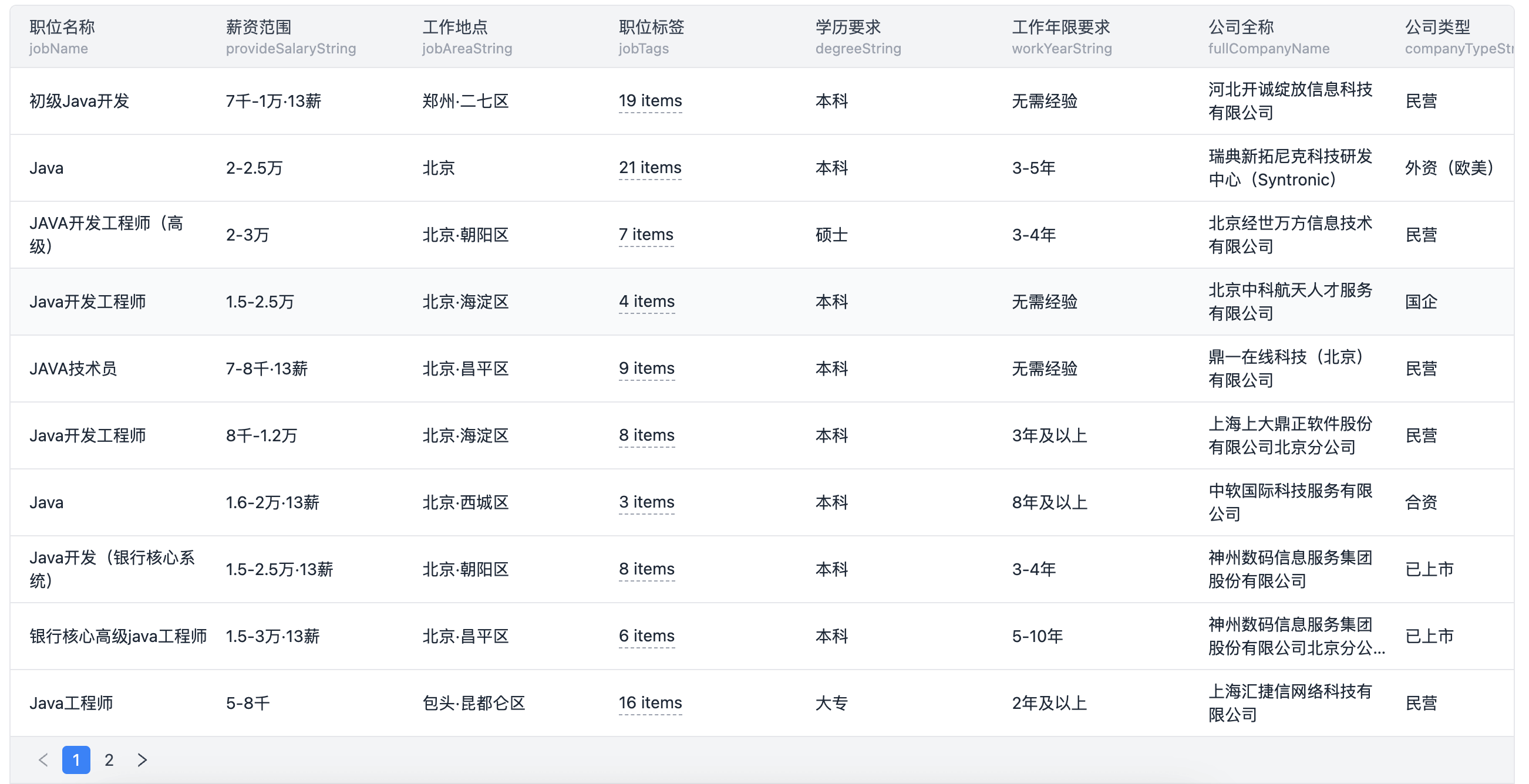
采集到的原始数据往往需要进一步清洗与分析,以便于洞察市场趋势、人才流动等有价值信息。
六、合规与道德边界
在进行网络数据采集时,务必遵守相关法律法规及网站的robots.txt协议,尊重数据版权,合法合规使用数据。
常见问题与解答
-
问:如何避免被网站封IP? 答:使用代理IP轮换、控制请求频率,模仿正常用户浏览行为。
-
问:爬虫抓取速度如何控制? 答:合理设置时间间隔,如每请求之间等待1-3秒,避免对目标网站造成过大压力。
-
问:遇到动态加载的数据怎么办? 答:对于Ajax加载的内容,可以分析其请求参数,直接请求数据API,或使用Selenium等工具模拟浏览器操作。
-
问:如何存储抓取到的数据? 答:可以选择MySQL、MongoDB等数据库,或使用CSV、Excel等文件格式保存,具体根据数据量和查询需求决定。
-
问:如何确保数据的时效性和准确性? 答:定期更新爬虫任务,设置数据校验逻辑,剔除重复或过期信息。
结语
掌握了爬虫技术,你不仅能够从前程无忧这样的大型招聘网站高效抓取岗位详情,还能广泛应用于其他领域的信息搜集与分析。对于企业而言,集蜂云平台(beeize.com)提供了更为便捷的数据采集解决方案,无需自建爬虫系统,即可享受海量任务调度、数据存储等一站式服务,让数据采集更高效、稳定,助力企业数字化转型。