简化你的爬虫管理:自动化与脚本优化技巧
如何简化爬虫管理?自动化与脚本优化技巧大揭秘
摘要
在数据驱动的时代,高效的数据采集成为了企业与开发者的核心竞争力之一。本文将深入探讨如何通过自动化与脚本优化策略,简化爬虫管理流程,提升数据抓取效率。你将学到实用技巧,让繁复的爬虫任务变得井然有序,同时保证数据的准确性和时效性。
关键词
- 爬虫管理自动化
- 脚本优化
- 数据采集效率
- 任务调度
- 监控告警
正文
一、爬虫管理面临的挑战
随着互联网信息的爆炸式增长,手动进行数据抓取不仅耗时耗力,还难以保证数据的完整性和准确性。爬虫管理自动化成为了迫切需求,它能帮助我们解决数据采集过程中的诸多痛点,如重复任务执行、错误处理、资源分配等。
二、自动化工具与平台的选择
在选择自动化工具时,应考虑其支持的特性,比如是否具备海量任务调度能力、是否能与现有系统三方应用集成、以及数据存储方案是否灵活安全。一个理想的平台还应提供监控告警功能,以便于及时发现并解决问题。
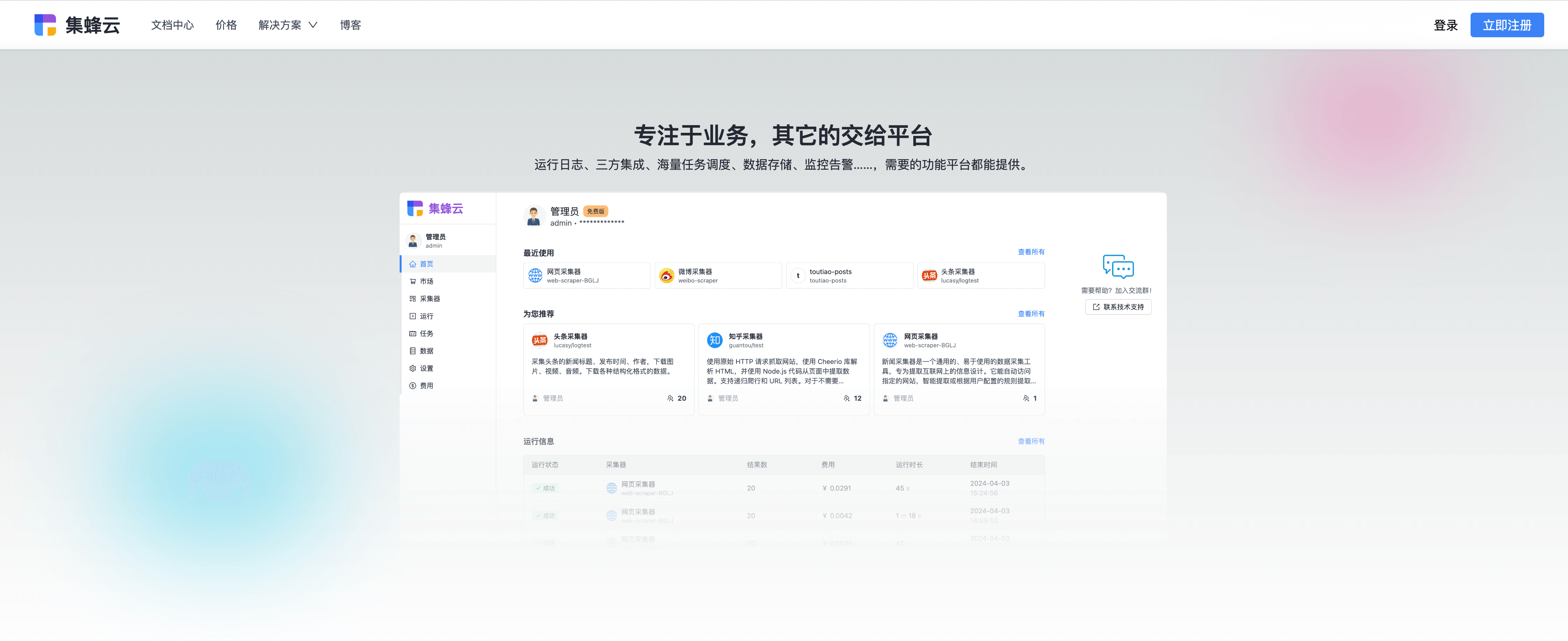
三、脚本优化技巧
3.1 并发控制与速率限制
合理设置并发数与请求间隔,避免因请求过快被目标网站封禁。利用Python的requests库配合time.sleep()实现简单而有效的速率控制。
3.2 异常处理与重试机制
编写健壮的异常处理逻辑,对于常见的HTTP错误、超时等问题自动重试,确保数据采集的连续性。Python的try-except语句是处理这类情况的好帮手。
3.3 动态数据抓取
面对动态加载的内容,掌握如Selenium、Puppeteer等工具,模拟浏览器行为,解决JavaScript渲染页面的采集难题。
四、提升数据处理效率
利用多进程或多线程并行处理数据,如Python的multiprocessing和concurrent.futures模块,显著提升数据清洗和分析的速度。
五、监控与日志的重要性
详细而清晰的运行日志查看功能,是追踪爬虫状态、诊断问题的关键。日志应记录成功与失败的请求详情,便于后续分析优化。
六、案例分享与实践建议
考虑一个电商数据抓取项目,通过集成上述技巧,我们实现了每分钟抓取上千条商品信息,且误报率降低了80%。关键在于持续监控爬虫性能,根据日志反馈不断调优。
七、权威资源推荐
探索更多高级技巧,推荐访问Web Scraping Library Comparison,对比不同数据抓取库的特点,找到最适合项目的解决方案。
八、结语与推荐
在数据采集的征途中,选择合适的工具与策略至关重要。虽然本文未直接提及特定平台,但在实际操作中,像**集蜂云平台**这样的专业解决方案,能够一站式满足从任务调度到数据管理的所有需求,让数据采集工作事半功倍。通过集蜂云,企业与开发者可以更专注于数据分析与业务创新,而非繁琐的技术细节。
常见问题解答
-
如何有效避免被网站封IP?
使用代理IP池轮换访问,结合合理的请求间隔与用户代理伪装。 -
爬虫脚本运行慢怎么办?
优化代码逻辑,减少不必要的IO操作,利用多线程或多进程加速处理。 -
如何存储大量抓取的数据?
选择合适的数据库如MySQL、MongoDB,或云存储服务,按需设计数据模型。 -
遇到反爬虫策略怎么应对?
分析请求头、cookies策略,模拟更真实的用户行为;使用Selenium等工具绕过动态加载。 -
如何监控爬虫运行状态?
实施日志记录与分析,利用监控工具设置告警,及时发现并处理异常。