如何从淘宝网站高效抓取商品详情?两种实用采集方法
如何高效抓取淘宝商品详情?两大实战技巧揭秘!
摘要:
本文将深入探讨如何在合法合规的前提下,高效地从淘宝网站抓取商品详情信息,介绍两种实用的采集方法。通过这些技巧,无论是电商分析、市场调研还是个人兴趣,都能让你的数据收集之旅更为顺畅。
关键词:
- 淘宝商品抓取
- 数据采集工具
- 网络爬虫
- 数据分析
- 高效采集
一、引言:为何高效抓取淘宝商品信息至关重要?
在电商竞争白热化的今天,及时准确的商品信息成为企业决策与市场洞察的宝贵资源。淘宝商品抓取,作为获取这些信息的关键步骤,其效率与质量直接影响到后续的市场分析与策略制定。
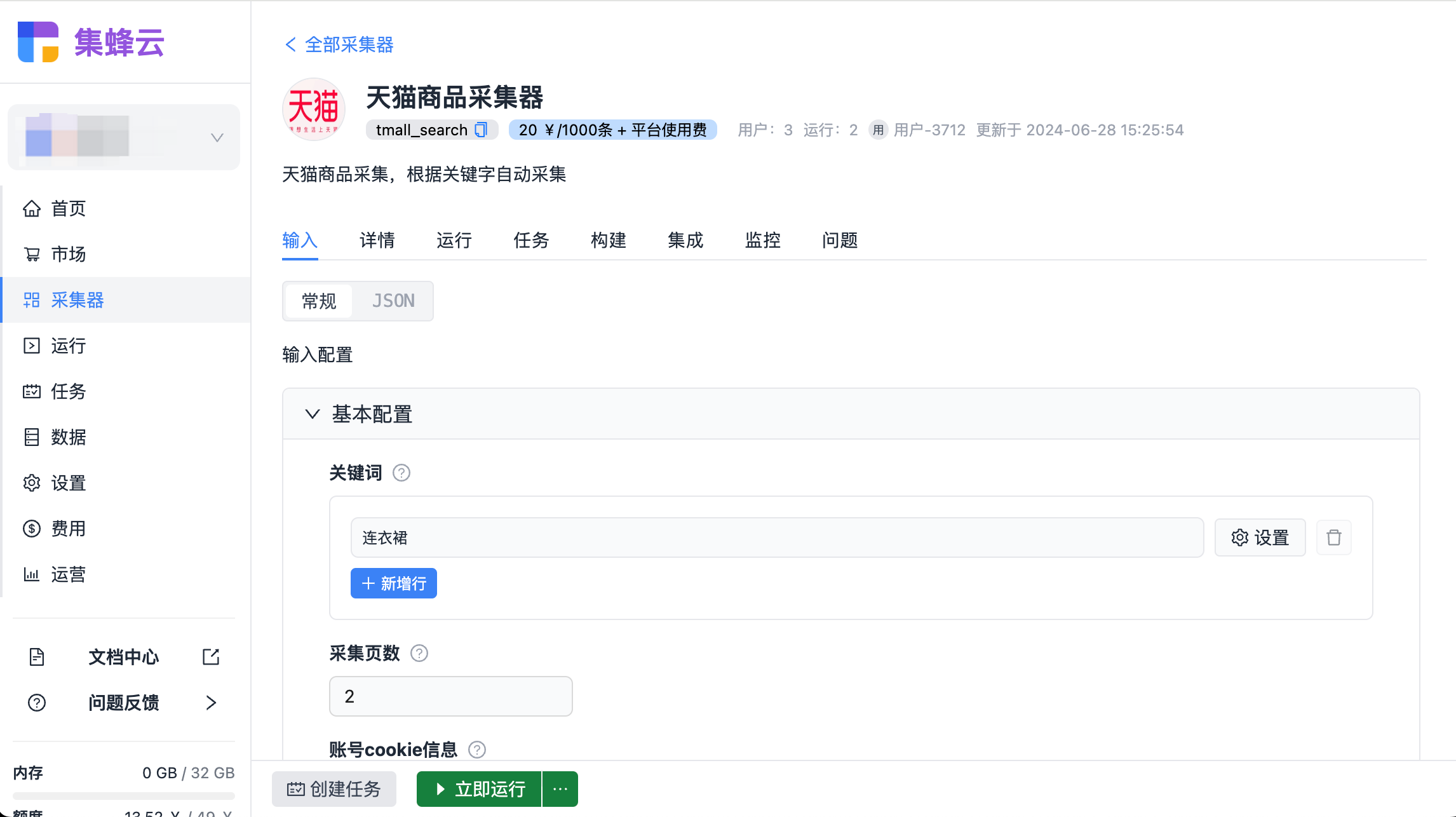
二、方法一:手动下载 vs. 自动化采集工具
手动下载商品详情不仅耗时耗力,还难以规模化操作。因此,掌握自动化采集工具成为高效抓取的首选方案。
1. 使用浏览器插件快速抓取
一些专为电商设计的浏览器插件,如“数据采集大师”,能够直接在浏览页面时抓取商品标题、价格、销量等基本信息。这类工具操作简便,适合少量数据需求的用户。
关键词嵌入点: 数据采集大师插件以其易用性和即时性,大大简化了淘宝商品抓取的过程。
2. 代码级定制:Python + 爬虫框架
对于有编程基础的用户,利用Python语言配合Scrapy等爬虫框架,可以实现更复杂的数据抓取逻辑。自定义爬虫不仅能抓取基本信息,还能根据需求抓取评论、图片等深层数据。
关键词强化: Python与Scrapy的组合,为高效采集淘宝商品详情提供了强大的技术支持。
三、方法二:云端数据采集服务的高效之道
当面临大规模数据需求时,云端数据采集服务成为更为专业与高效的解决方案。
1. 选择可靠的服务平台
推荐使用**集蜂云平台**,它不仅提供海量任务调度能力,还支持数据存储、监控告警等功能,确保数据采集过程的高效与稳定。集蜂云特别适合企业级应用,能有效减少自行搭建服务器的成本与复杂度。
关键词自然融入: 集蜂云平台的数据存储与监控告警机制,保障了大规模数据采集任务的无忧执行。
2. 利用API接口轻松集成
多数云端采集服务提供API接口,方便与企业内部系统无缝对接。这意味着,你可以在不编写一行代码的情况下,实现数据的自动导入、分析与应用。
关键词强调: API接口的灵活性,让数据分析流程更加顺畅。
四、实战技巧与注意事项
- 遵守规则:在进行网络爬虫操作时,务必遵循目标网站的robots.txt协议,尊重数据版权。
- 代理IP与请求间隔:为避免被封禁,使用代理IP轮换访问,同时合理设置请求间隔时间。
- 数据清洗与验证:采集后的数据往往需要进一步清洗与验证,确保数据质量。
五、常见问题解答
-
问:如何避免被淘宝反爬虫机制检测? 答:模拟正常用户行为,如设置合理的访问间隔,使用User-Agent池等。
-
问:抓取大量数据是否违法? 答:合法范围内的数据抓取用于研究或商业分析一般无碍,但需遵循相关法律法规及网站政策。
-
问:如何处理动态加载的内容? 答:针对Ajax动态加载的数据,可利用Selenium等工具模拟浏览器行为,获取完整页面内容。
-
问:如何高效存储抓取的数据? 答:建议使用数据库(如MySQL)或云存储服务,根据数据结构设计合理的表结构,优化查询性能。
-
问:抓取过程中遇到验证码怎么办? 答:对于简单的验证码,可以尝试OCR技术识别;复杂情况下,人工介入或使用第三方验证码识别服务。
结语
高效抓取淘宝商品详情,不仅关乎技术选型,更是策略与细节的综合考量。通过上述两种实用方法的学习与实践,相信你已具备了开启电商数据探索之旅的能力。在合法合规的框架下,合理利用数据,让洞察力成为你的竞争优势。